RestFul API 简明教程
何为 API?
API(Application Programming Interface) 翻译过来是应用程序编程接口的意思。
我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。
但是, API 不仅仅代表后端系统暴露的接口,像框架中提供的方法也属于 API 的范畴。
为了方便大家理解,我再列举几个例子 🌰:
- 你通过某电商网站搜索某某商品,电商网站的前端就调用了后端提供了搜索商品相关的 API。
- 你使用 JDK 开发 Java 程序,想要读取用户的输入的话,你就需要使用 JDK 提供的 IO 相关的 API。
- ……
你可以把 API 理解为程序与程序之间通信的桥梁,其本质就是一个函数而已。另外,API 的使用也不是没有章法的,它的规则由(比如数据输入和输出的格式)API 提供方制定。
何为 RESTful API?
RESTful API 经常也被叫做 REST API,它是基于 REST 构建的 API。这个 REST 到底是什么,我们后文在讲,涉及到的概念比较多。
如果你看 RESTful API 相关的文章的话一般都比较晦涩难懂,主要是因为 REST 涉及到的一些概念比较难以理解。但是,实际上,我们平时开发用到的 RESTful API 的知识非常简单也很容易概括!
举个例子,如果我给你下面两个 API 你是不是立马能知道它们是干什么用的!这就是 RESTful API 的强大之处!
|
|
RESTful API 可以让你看到 URL+Http Method 就知道这个 URL 是干什么的,让你看到了 HTTP 状态码(status code)就知道请求结果如何。
像咱们在开发过程中设计 API 的时候也应该至少要满足 RESTful API 的最基本的要求(比如接口中尽量使用名词,使用 POST 请求创建资源,DELETE 请求删除资源等等,示例:GET /notes/id:获取某个指定 id 的笔记的信息)。
解读 REST
REST 是 REpresentational State Transfer 的缩写。这个词组的翻译过来就是“表现层状态转化”。
这样理解起来甚是晦涩,实际上 REST 的全称是 Resource Representational State Transfer ,直白地翻译过来就是 “资源”在网络传输中以某种“表现形式”进行“状态转移” 。如果还是不能继续理解,请继续往下看,相信下面的讲解一定能让你理解到底啥是 REST 。
我们分别对上面涉及到的概念进行解读,以便加深理解,实际上你不需要搞懂下面这些概念,也能看懂我下一部分要介绍到的内容。不过,为了更好地能跟别人扯扯 “RESTful API”我建议你还是要好好理解一下!
- 资源(Resource):我们可以把真实的对象数据称为资源。一个资源既可以是一个集合,也可以是单个个体。比如我们的班级 classes 是代表一个集合形式的资源,而特定的 class 代表单个个体资源。每一种资源都有特定的 URI(统一资源标识符)与之对应,如果我们需要获取这个资源,访问这个 URI 就可以了,比如获取特定的班级:
/class/12。另外,资源也可以包含子资源,比如/classes/classId/teachers:列出某个指定班级的所有老师的信息 - 表现形式(Representational):“资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式比如
json,xml,image,txt等等叫做它的"表现层/表现形式”。 - 状态转移(State Transfer):大家第一眼看到这个词语一定会很懵逼?内心 BB:这尼玛是啥啊? 大白话来说 REST 中的状态转移更多地描述的服务器端资源的状态,比如你通过增删改查(通过 HTTP 动词实现)引起资源状态的改变。ps:互联网通信协议 HTTP 协议,是一个无状态协议,所有的资源状态都保存在服务器端。
综合上面的解释,我们总结一下什么是 RESTful 架构:
- 每一个 URI 代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现形式比如
json,xml,image,txt等等; - 客户端通过特定的 HTTP 动词,对服务器端资源进行操作,实现"表现层状态转化"。
RESTful API 规范
动作
GET:请求从服务器获取特定资源。举个例子:GET /classes(获取所有班级)POST:在服务器上创建一个新的资源。举个例子:POST /classes(创建班级)PUT:更新服务器上的资源(客户端提供更新后的整个资源)。举个例子:PUT /classes/12(更新编号为 12 的班级)DELETE:从服务器删除特定的资源。举个例子:DELETE /classes/12(删除编号为 12 的班级)PATCH:更新服务器上的资源(客户端提供更改的属性,可以看做作是部分更新),使用的比较少,这里就不举例子了。
路径(接口命名)
路径又称"终点"(endpoint),表示 API 的具体网址。实际开发中常见的规范如下:
- 网址中不能有动词,只能有名词,API 中的名词也应该使用复数。 因为 REST 中的资源往往和数据库中的表对应,而数据库中的表都是同种记录的"集合"(collection)。如果 API 调用并不涉及资源(如计算,翻译等操作)的话,可以用动词。比如:
GET /calculate?param1=11¶m2=33。 - 不用大写字母,建议用中杠 - 不用下杠 _ 。比如邀请码写成
invitation-code而不是 invitation_code 。 - 善用版本化 API。当我们的 API 发生了重大改变而不兼容前期版本的时候,我们可以通过 URL 来实现版本化,比如
http://api.example.com/v1、http://apiv1.example.com。版本不必非要是数字,只是数字用的最多,日期、季节都可以作为版本标识符,项目团队达成共识就可。 - 接口尽量使用名词,避免使用动词。 RESTful API 操作(HTTP Method)的是资源(名词)而不是动作(动词)。
Talk is cheap!来举个实际的例子来说明一下吧!现在有这样一个 API 提供班级(class)的信息,还包括班级中的学生和教师的信息,则它的路径应该设计成下面这样。
|
|
反例:
|
|
理清资源的层次结构,比如业务针对的范围是学校,那么学校会是一级资源:/schools,老师: /schools/teachers,学生: /schools/students 就是二级资源。
过滤信息(Filtering)
如果我们在查询的时候需要添加特定条件的话,建议使用 url 参数的形式。比如我们要查询 state 状态为 active 并且 name 为 guidegege 的班级:
|
|
比如我们要实现分页查询:
|
|
状态码(Status Codes)
状态码范围:
| 2xx:成功 | 3xx:重定向 | 4xx:客户端错误 | 5xx:服务器错误 |
|---|---|---|---|
| 200 成功 | 301 永久重定向 | 400 参数错误 | 500 服务器错误 |
| 201 创建 | 304 资源未修改 | 401 未授权 | 502 网关错误 |
| 403 禁止访问 | 504 网关超时 | ||
| 404 未找到 | |||
| 405 请求方法不对 |
软件工程简明教程
何为软件工程?
1968 年 NATO(北大西洋公约组织)提出了软件危机(Software crisis)一词。同年,为了解决软件危机问题,“软件工程”的概念诞生了。一门叫做软件工程的学科也就应运而生。
随着时间的推移,软件工程这门学科也经历了一轮又一轮的完善,其中的一些核心内容比如软件开发模型越来越丰富实用!
什么是软件危机呢?
简单来说,软件危机描述了当时软件开发的一个痛点:我们很难高效地开发出质量高的软件。
Dijkstra(Dijkstra 算法的作者) 在 1972 年图灵奖获奖感言中也提高过软件危机,他是这样说的:“导致软件危机的主要原因是机器变得功能强大了几个数量级!坦率地说:只要没有机器,编程就完全没有问题。当我们有一些弱小的计算机时,编程成为一个温和的问题,而现在我们有了庞大的计算机,编程也同样成为一个巨大的问题”。
说了这么多,到底什么是软件工程呢?
工程是为了解决实际的问题将理论应用于实践。软件工程指的就是将工程思想应用于软件开发。
上面是我对软件工程的定义,我们再来看看比较权威的定义。IEEE 软件工程汇刊给出的定义是这样的: (1)将系统化的、规范的、可量化的方法应用到软件的开发、运行及维护中,即将工程化方法应用于软件。 (2)在(1)中所述方法的研究。
总之,软件工程的终极目标就是:在更少资源消耗的情况下,创造出更好、更容易维护的软件。
软件开发过程
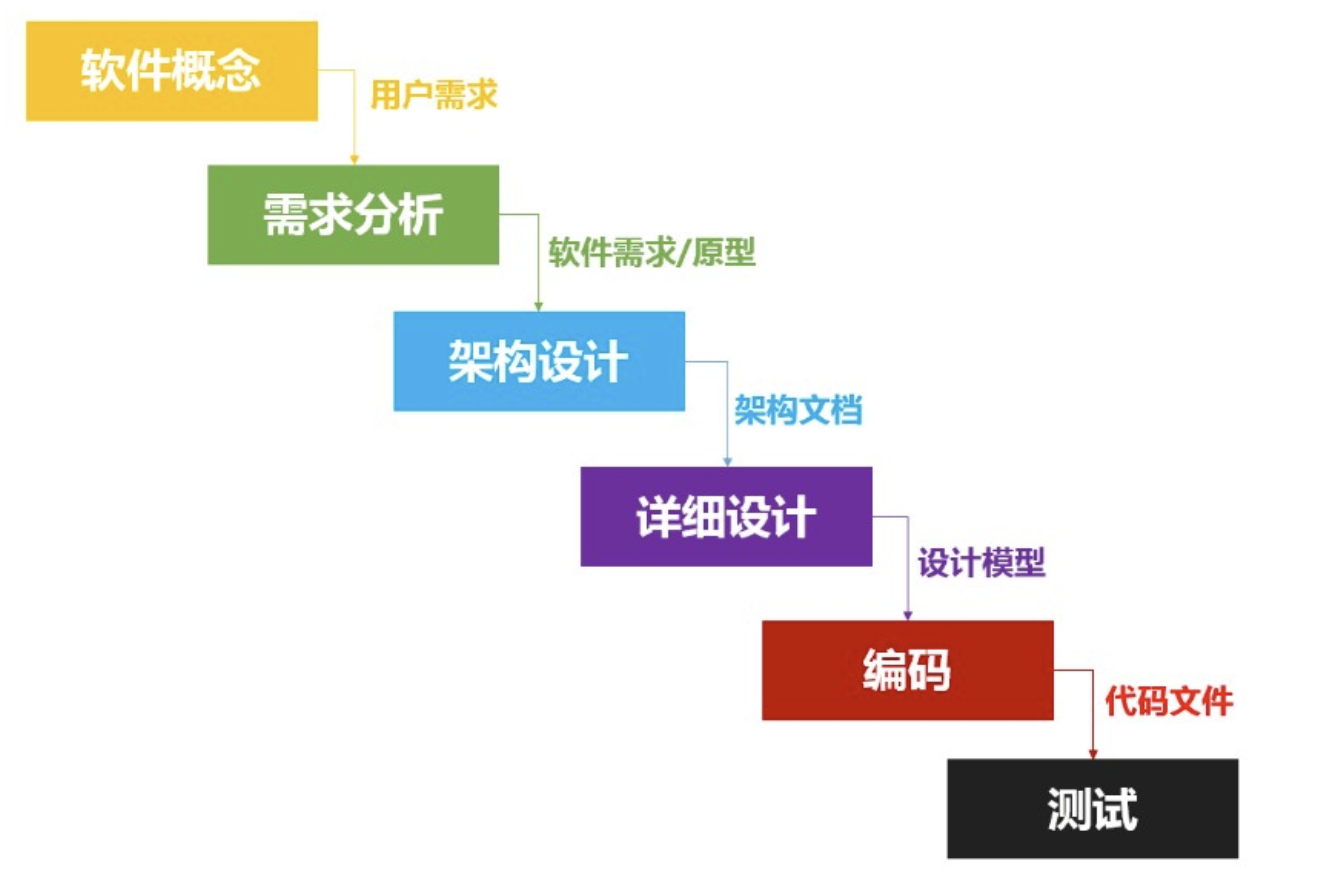
软件开发过程(英语:software development process),或软件过程(英语:software process),是软件开发的开发生命周期(software development life cycle),其各个阶段实现了软件的需求定义与分析、设计、实现、测试、交付和维护。软件过程是在开发与构建系统时应遵循的步骤,是软件开发的路线图。
- 需求分析:分析用户的需求,建立逻辑模型。
- 软件设计:根据需求分析的结果对软件架构进行设计。
- 编码:编写程序运行的源代码。
- 测试 : 确定测试用例,编写测试报告。
- 交付:将做好的软件交付给客户。
- 维护:对软件进行维护比如解决 bug,完善功能。
软件开发过程只是比较笼统的层面上,一定义了一个软件开发可能涉及到的一些流程。
软件开发模型更具体地定义了软件开发过程,对开发过程提供了强有力的理论支持。
软件开发模型
软件开发模型有很多种,比如瀑布模型(Waterfall Model)、快速原型模型(Rapid Prototype Model)、V 模型(V-model)、W 模型(W-model)、敏捷开发模型。其中最具有代表性的还是 瀑布模型 和 敏捷开发 。
瀑布模型 定义了一套完成的软件开发周期,完整地展示了一个软件的的生命周期。
敏捷开发模型 是目前使用的最多的一种软件开发模型。MBA 智库百科对敏捷开发的描述是这样的:
敏捷开发 是一种以人为核心、迭代、循序渐进的开发方法。在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
像现在比较常见的一些概念比如 持续集成、重构、小版本发布、低文档、站会、结对编程、测试驱动开发 都是敏捷开发的核心。
软件开发的基本策略
软件复用
我们在构建一个新的软件的时候,不需要从零开始,通过复用已有的一些轮子(框架、第三方库等)、设计模式、设计原则等等现成的物料,我们可以更快地构建出一个满足要求的软件。
像我们平时接触的开源项目就是最好的例子。我想,如果不是开源,我们构建出一个满足要求的软件,耗费的精力和时间要比现在多的多!
分而治之
构建软件的过程中,我们会遇到很多问题。我们可以将一些比较复杂的问题拆解为一些小问题,然后,一一攻克。
我结合现在比较火的软件设计方法—领域驱动设计(Domain Driven Design,简称 DDD)来说说。
在领域驱动设计中,很重要的一个概念就是领域(Domain),它就是我们要解决的问题。在领域驱动设计中,我们要做的就是把比较大的领域(问题)拆解为若干的小领域(子域)。
除此之外,分而治之也是一个比较常用的算法思想,对应的就是分治算法。如果你想了解分治算法的话,推荐你看一下北大的《算法设计与分析 Design and Analysis of Algorithms》。
逐步演进
软件开发是一个逐步演进的过程,我们需要不断进行迭代式增量开发,最终交付符合客户价值的产品。
这里补充一个在软件开发领域,非常重要的概念:MVP(Minimum Viable Product,最小可行产品)。
这个最小可行产品,可以理解为刚好能够满足客户需求的产品。下面这张图片把这个思想展示的非常精髓。
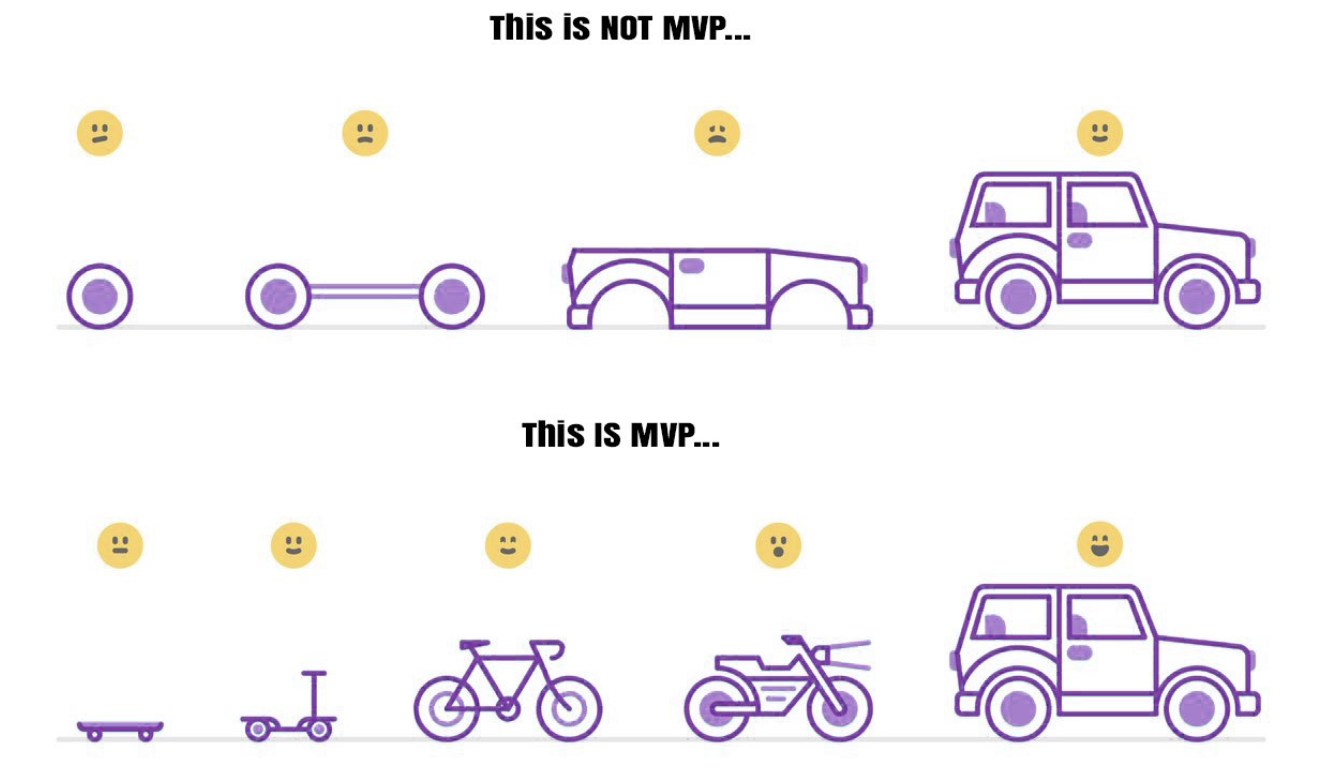
利用最小可行产品,我们可以也可以提早进行市场分析,这对于我们在探索产品不确定性的道路上非常有帮助。可以非常有效地指导我们下一步该往哪里走。
优化折中
软件开发是一个不断优化改进的过程。任何软件都有很多可以优化的点,不可能完美。我们需要不断改进和提升软件的质量。
但是,也不要陷入这个怪圈。要学会折中,在有限的投入内,以最有效的方式提高现有软件的质量。
命名指南
常见命名规则以及适用场景
这里只介绍 3 种最常见的命名规范。
驼峰命名法(CamelCase)
驼峰命名法应该我们最常见的一个,这种命名方式使用大小写混合的格式来区别各个单词,并且单词之间不使用空格隔开或者连接字符连接的命名方式
驼峰命名法(UpperCamelCase)
类名需要使用大驼峰命名法(UpperCamelCase)
正例:
|
|
反例:
|
|
驼峰命名法(lowerCamelCase)
方法名、参数名、成员变量、局部变量需要使用小驼峰命名法(lowerCamelCase)。
正例:
|
|
反例:
|
|
蛇形命名法(snake_case)
测试方法名、常量、枚举名称需要使用蛇形命名法(snake_case)
在蛇形命名法中,各个单词之间通过下划线“_”连接,比如should_get_200_status_code_when_request_is_valid、CLIENT_CONNECT_SERVER_FAILURE。
蛇形命名法的优势是命名所需要的单词比较多的时候,比如我把上面的命名通过小驼峰命名法给大家看一下:“shouldGet200StatusCodeWhenRequestIsValid”。
感觉如何? 相比于使用蛇形命名法(snake_case)来说是不是不那么易读?
正例:
|
|
反例:
|
|
串式命名法(kebab-case)
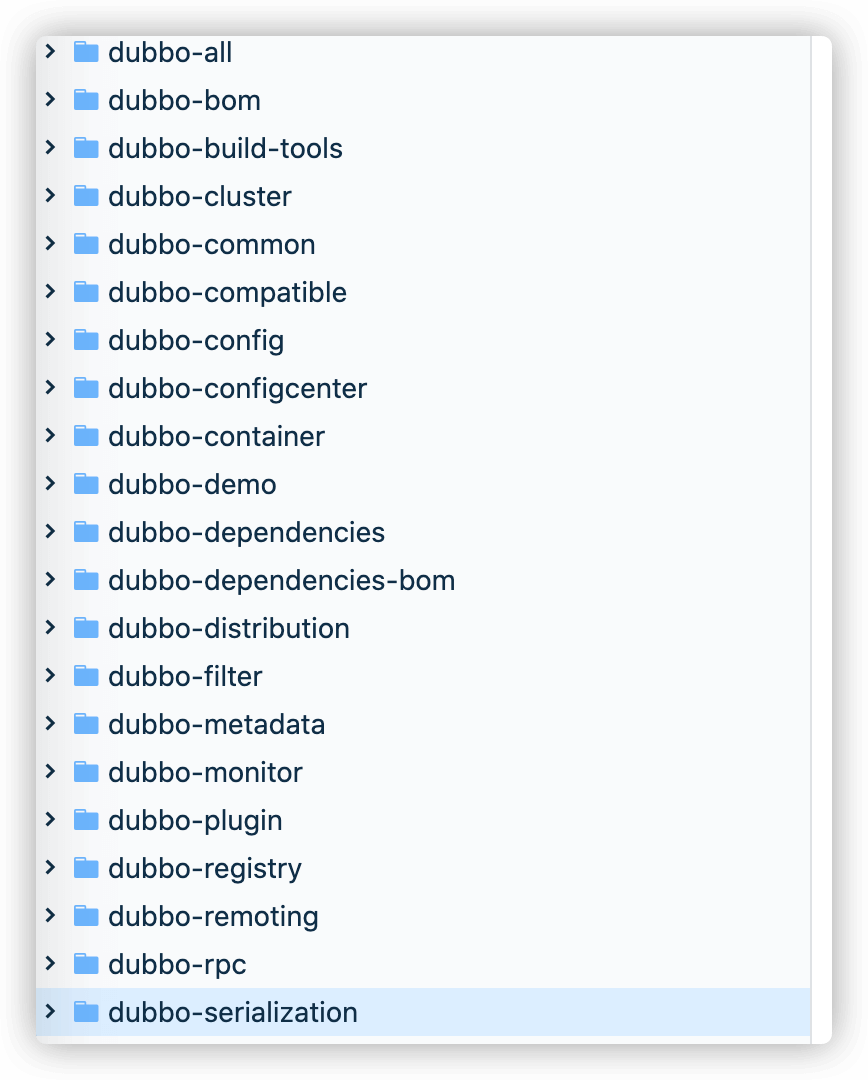
在串式命名法中,各个单词之间通过连接符“-”连接,比如dubbo-registry。
建议项目文件夹名称使用串式命名法(kebab-case),比如 dubbo 项目的各个模块的命名是下面这样的。
常见命名规范
Java 语言基本命名规范
1、类名需要使用大驼峰命名法(UpperCamelCase)风格。方法名、参数名、成员变量、局部变量需要使用小驼峰命名法(lowerCamelCase)。
2、测试方法名、常量、枚举名称需要使用蛇形命名法(snake_case),比如should_get_200_status_code_when_request_is_valid、CLIENT_CONNECT_SERVER_FAILURE。并且,测试方法名称要求全部小写,常量以及枚举名称需要全部大写。
3、项目文件夹名称使用串式命名法(kebab-case),比如dubbo-registry。
4、包名统一使用小写,尽量使用单个名词作为包名,各个单词通过 “.” 分隔符连接,并且各个单词必须为单数。
正例:org.apache.dubbo.common.threadlocal
反例:org.apache_dubbo.Common.threadLocals
5、抽象类命名使用 Abstract 开头。
|
|
6、异常类命名使用 Exception 结尾。
|
|
7、测试类命名以它要测试的类的名称开始,以 Test 结尾。
|
|
POJO 类中布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
如果模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式。
命名易读性规范
1、为了能让命名更加易懂和易读,尽量不要缩写/简写单词,除非这些单词已经被公认可以被这样缩写/简写。比如 CustomThreadFactory 不可以被写成 ~~CustomTF 。
2、命名不像函数一样要尽量追求短,可读性强的名字优先于简短的名字,虽然可读性强的名字会比较长一点。 这个对应我们上面说的第 1 点。
3、避免无意义的命名,你起的每一个名字都要能表明意思。
正例:UserService userService; int userCount;
反例: UserService service int count
4、避免命名过长(50 个字符以内最好),过长的命名难以阅读并且丑陋。
5、不要使用拼音,更不要使用中文。 不过像 alibaba、wuhan、taobao 这种国际通用名词可以当做英文来看待。
正例:discount
反例:dazhe
代码重构
学习重构必看的一本神书《重构:改善代码既有设计》从两个角度给出了重构的定义:
- 重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
- 重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
用更贴近工程师的语言来说:重构就是利用设计模式(如组合模式、策略模式、责任链模式)、软件设计原则(如 SOLID 原则、YAGNI 原则、KISS 原则)和重构手段(如封装、继承、构建测试体系)来让代码更容易理解,更易于修改。
软件设计原则指导着我们组织和规范代码,同时,重构也是为了能够尽量设计出尽量满足软件设计原则的软件。
正确重构的核心在于 步子一定要小,每一步的重构都不会影响软件的正常运行,可以随时停止重构。
为什么要重构?
在上面介绍重构定义的时候,我从比较抽象的角度介绍了重构的好处:重构的主要目的主要是提升代码&架构的灵活性/可扩展性以及复用性。
如果对应到一个真实的项目,重构具体能为我们带来什么好处呢?
- 让代码更容易理解:通过添加注释、命名规范、逻辑优化等手段可以让我们的代码更容易被理解;
- 避免代码腐化:通过重构干掉坏味道代码;
- 加深对代码的理解:重构代码的过程会加深你对某部分代码的理解;
- 发现潜在 bug:是这样的,很多潜在的 bug ,都是我们在重构的过程中发现的;
- ……
看了上面介绍的关于重构带来的好处之后,你会发现重构的最终目标是 提高软件开发速度和质量 。
重构并不会减慢软件开发速度,相反,如果代码质量和软件设计较差,当我们想要添加新功能的话,开发速度会越来越慢。到了最后,甚至都有想要重写整个系统的冲动。
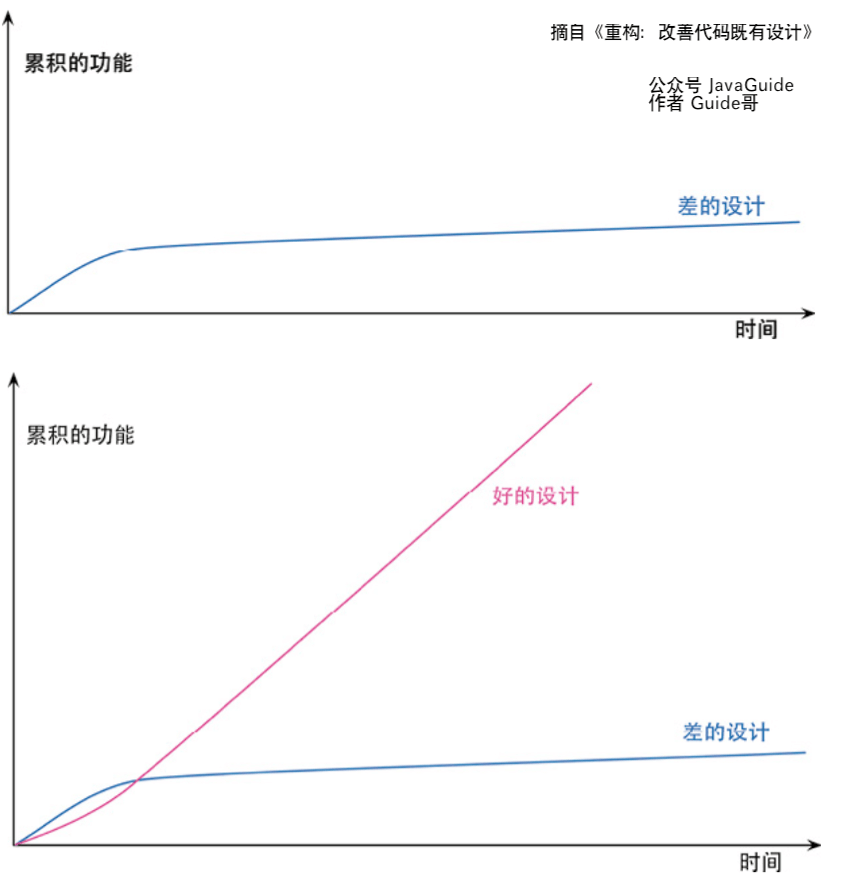
《重构:改善代码既有设计》这本书中这样说:
重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值。
何时进行重构?
重构在是开发过程中随时可以进行的,见机行事即可,并不需要单独分配一两天的时间专门用来重构。
提交代码之前
《重构:改善代码既有设计》这本书介绍了一个 营地法则 的概念:
编程时,需要遵循营地法则:保证你离开时的代码库一定比来时更健康。
这个概念表达的核心思想其实很简单:在你提交代码的之前,花一会时间想一想,我这次的提交是让项目代码变得更健康了,还是更腐化了,或者说没什么变化?
项目团队的每一个人只有保证自己的提交没有让项目代码变得更腐化,项目代码才会朝着健康的方向发展。
当我们离开营地(项目代码)的时候,请不要留下垃圾!尽量确保营地变得更干净了!
开发一个新功能之后&之前
在开发一个新功能之后,我们应该回过头看看是不是有可以改进的地方。在添加一个新功能之前,我们可以思考一下自己是否可以重构代码以让新功能的开发更容易。
一个新功能的开发不应该仅仅只有功能验证通过那么简单,我们还应该尽量保证代码质量。
有一个两顶帽子的比喻:在我开发新功能之前,我发现重构可以让新功能的开发更容易,于是我戴上了重构的帽子。重构之后,我换回原来的帽子,继续开发新能功能。新功能开发完成之后,我又发现自己的代码难以理解,于是我又戴上了重构帽子。比较好的开发状态就是就是这样在重构和开发新功能之间来回切换。
Code Review 之后
Code Review 可以非常有效提高代码的整体质量,它会帮助我们发现代码中的坏味道以及可能存在问题的地方。并且, Code Review 可以帮助项目团队其他程序员理解你负责的业务模块,有效避免人员方面的单点风险。
经历一次 Code Review ,你的代码可能会收到很多改进建议。
捡垃圾式重构
当我们发现垃圾代码的时候,如果我们不想停下手头自己正在做的工作,但又不想放着垃圾不管,我们可以这样做:
- 如果这个垃圾很容易重构的话,我们可以立即重构它。
- 如果这个垃圾不太容易重构的话,我们可以先记录下来,当完成当下的任务再回来重构它。
捡垃圾式重构
当我们发现坏味道代码(垃圾)的时候,如果我们不想停下手头自己正在做的工作,但又不想放着垃圾不管,我们可以这样做:
- 如果这个垃圾很容易重构的话,我们可以立即重构它。
- 如果这个垃圾不太容易重构的话,我们可以先记录下来,当完成当下的任务再回来重构它。
重构有哪些注意事项?
单元测试是重构的保护网
单元测试可以为重构提供信心,降低重构的成本。我们要像重视生产代码那样,重视单元测试。
另外,多提一句:持续集成也要依赖单元测试,当持续集成服务自动构建新代码之后,会自动运行单元测试来发现代码错误。
怎样才能算单元测试呢? 网上的定义很多,很抽象,很容易把人给看迷糊了。我觉得对于单元测试的定义主要取决于你的项目,一个函数甚至是一个类都可以看作是一个单元。就比如说我们写了一个计算个人股票收益率的方法,我们为了验证它的正确性专门为它写了一个单元测试。再比如说我们代码有一个类专门负责数据脱敏,我们为了验证脱敏是否符合预期专门为这个类写了一个单元测试。
单元测试也是需要重构或者修改的。 《代码整洁之道:敏捷软件开发手册》这本书这样写到:
测试代码需要随着生产代码的演进而修改,如果测试不能保持整洁,只会越来越难修改。
不要为了重构而重构
重构一定是要为项目带来价值的! 某些情况下我们不应该进行重构:
- 学习了某个设计模式/工程实践之后,不顾项目实际情况,刻意使用在项目上(避免货物崇拜编程);
- 项目进展比较急的时候,重构项目调用的某个 API 的底层代码(重构之后对项目调用这个 API 并没有带来什么价值);
- 重写比重构更容易更省事;
- ……
遵循方法
《重构:改善代码既有设计》这本书中列举除了代码常见的一些坏味道(比如重复代码、过长函数)和重构手段(如提炼函数、提炼变量、提炼类)。我们应该花时间去学习这些重构相关的理论知识,并在代码中去实践这些重构理论。
如何练习重构?
除了可以在重构项目代码的过程中练习精进重构之外,你还可以有下面这些手段:
- 重构实战练习:通过几个小案例一步一步带你学习重构!
- 设计模式+重构学习网站:免费在线学习代码重构、 设计模式、 SOLID 原则 (单一职责、 开闭原则、 里氏替换、 接口隔离以及依赖反转) 。
- IDEA 官方文档的代码重构教程:教你如何使用 IDEA 进行重构。
单元测试指南
何谓单元测试?
维基百科是这样介绍单元测试的:
在计算机编程中,单元测试(Unit Testing)是针对程序模块(软件设计的最小单位)进行的正确性检验测试工作。
程序单元是应用的 最小可测试部件 。在过程化编程中,一个单元就是单个程序、函数、过程等;对于面向对象编程,最小单元就是方法,包括基类(超类)、抽象类、或者派生类(子类)中的方法。
由于每个单元有独立的逻辑,在做单元测试时,为了隔离外部依赖,确保这些依赖不影响验证逻辑,我们经常会用到 Fake、Stub 与 Mock 。
关于 Fake、Mock 与 Stub 这几个概念的解读,可以看看这篇文章:测试中 Fakes、Mocks 以及 Stubs 概念明晰 - 王下邀月熊 - 2018 。
为什么需要单元测试?
为重构保驾护航
单元测试可以为重构提供信心,降低重构的成本。我们要像重视生产代码那样,重视单元测试。
每个开发者都会经历重构,重构后把代码改坏了的情况并不少见,很可能你只是修改了一个很简单的方法就导致系统出现了一个比较严重的错误。
如果有了单元测试的话,就不会存在这个隐患了。写完一个类,把单元测试写了,确保这个类逻辑正确;写第二个类,单元测试…..写 100 个类,道理一样,每个类做到第一点“保证逻辑正确性”,100 个类拼在一起肯定不出问题。你大可以放心一边重构,一边运行 APP;而不是整体重构完,提心吊胆地 run。
提高代码质量
由于每个单元有独立的逻辑,做单元测试时需要隔离外部依赖,确保这些依赖不影响验证逻辑。因为要把各种依赖分离,单元测试会促进工程进行组件拆分,整理工程依赖关系,更大程度减少代码耦合。这样写出来的代码,更好维护,更好扩展,从而提高代码质量。
减少 bug
一个机器,由各种细小的零件组成,如果其中某件零件坏了,机器运行故障。必须保证每个零件都按设计图要求的规格,机器才能正常运行。
一个可单元测试的工程,会把业务、功能分割成规模更小、有独立的逻辑部件,称为单元。单元测试的目标,就是保证各个单元的逻辑正确性。单元测试保障工程各个“零件”按“规格”(需求)执行,从而保证整个“机器”(项目)运行正确,最大限度减少 bug。
快速定位 bug
如果程序有 bug,我们运行一次全部单元测试,找到不通过的测试,可以很快地定位对应的执行代码。修复代码后,运行对应的单元测试;如还不通过,继续修改,运行测试…..直到测试通过。
持续集成依赖单元测试
持续集成需要依赖单元测试,当持续集成服务自动构建新代码之后,会自动运行单元测试来发现代码错误。
谁逼你写单元测试?
领导要求
有些经验丰富的领导,或多或少都会要求团队写单元测试。对于有一定工作经验的队友,这要求挺合理;对于经验尚浅的、毕业生,恐怕要死要活了,连代码都写不好,还要写单元测试,are you kidding me?
培训新人单元测试用法,是一项艰巨的任务。新人代码风格未形成,也不知道单元测试多重要,强制单元测试会让他们感到困惑,没办法按自己思路写代码。
大牛都写单元测试
国外很多家喻户晓的开源项目,都有大量单元测试。例如,retrofit、okhttp、butterknife…. 国外大牛都写单元测试,我们也写吧!
很多读者都有这种想法,一开始满腔热血。当真要对自己项目单元测试时,便困难重重,很大原因是项目对单元测试不友好。最后只能对一些不痛不痒的工具类做单元测试,久而久之,当初美好愿望也不了了之。
保住面子
都是有些许年经验的老鸟,还天天被测试同学追 bug,好意思么?花多一点时间写单元测试,确保没低级 bug,还能彰显大牛风范,何乐而不为?
心虚
笔者也是个不太相信自己代码的人,总觉得哪里会突然冒出莫名其妙的 bug,也怕别人不小心改了自己的代码(被害妄想症),新版本上线提心吊胆……花点时间写单元测试,有事没事跑一下测试,确保原逻辑没问题,至少能睡安稳一点。
TDD 测试驱动开发
何谓 TDD?
TDD 即 Test-Driven Development( 测试驱动开发),这是敏捷开发的一项核心实践和技术,也是一种设计方法论。
TDD 原理是开发功能代码之前,先编写测试用例代码,然后针对测试用例编写功能代码,使其能够通过。
TDD 的节奏:“红 - 绿 - 重构”。
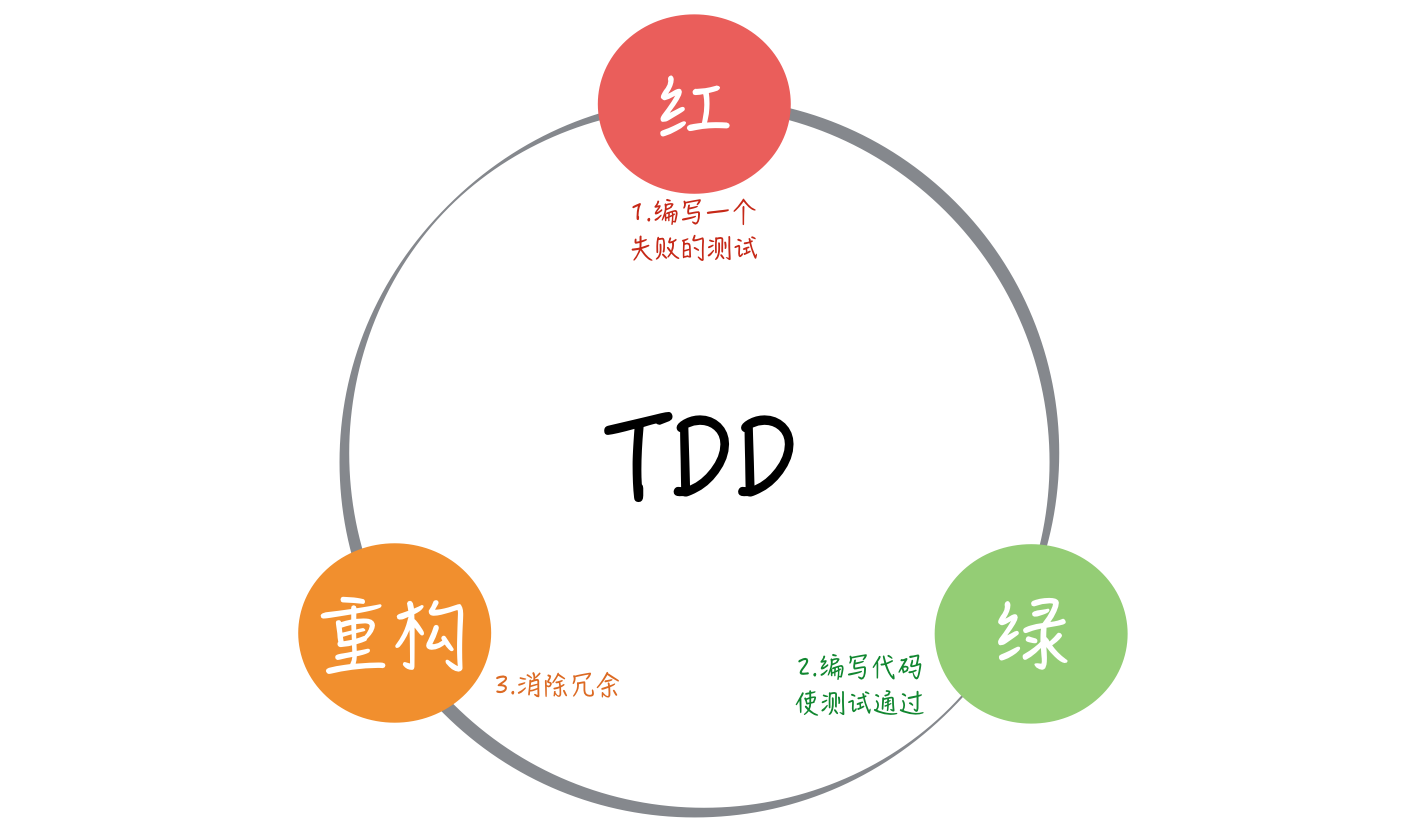
由于 TDD 对开发人员要求非常高,跟传统开发思维不一样,因此实施起来相当困难。
TDD 在很多人眼中是不实用的,一来他们并不理解测试“驱动”开发的含义,但更重要的是,他们很少会做任务分解。而任务分解是做好 TDD 的关键点。只有把任务分解到可以测试的地步,才能够有针对性地写测试。
TDD 优缺点分析
测试驱动开发有好处也有坏处。因为每个测试用例都是根据需求来的,或者说把一个大需求分解成若干小需求编写测试用例,所以测试用例写出来后,开发者写的执行代码,必须满足测试用例。如果测试不通过,则修改执行代码,直到测试用例通过。
优点:
- 帮你整理需求,梳理思路;
- 帮你设计出更合理的接口(空想的话很容易设计出屎);
- 减小代码出现 bug 的概率;
- 提高开发效率(前提是正确且熟练使用 TDD)。
缺点:
- 能用好 TDD 的人非常少,看似简单,实则门槛很高;
- 投入开发资源(时间和精力)通常会更多;
- 由于测试用例在未进行代码设计前写;很有可能限制开发者对代码整体设计;
- 可能引起开发人员不满情绪,我觉得这点很严重,毕竟不是人人都喜欢单元测试,尽管单元测试会带给我们相当多的好处。
相关阅读:如何用正确的姿势打开 TDD? - 陈天 - 2017
单测框架如何选择?
对于单测来说,目前常用的单测框架有:JUnit、Mockito、Spock、PowerMock、JMockit、TestableMock 等等。
JUnit 几乎是默认选择,但是其不支持 Mock,因此我们还需要选择一个 Mock 工具。Mockito 和 Spock 是最主流的两款 Mock 工具,一般都是在这两者中选择。
究竟是选择 Mockito 还是 Spock 呢?我这里做了一些简单的对比分析:
- Spock 没办法 Mock 静态方法和私有方法 ,Mockito 3.4.0 以后,支持静态方法的 Mock,具体可以看这个 issue:https://github.com/mockito/mockito/issues/1013,具体教程可以看这篇文章:https://www.baeldung.com/mockito-mock-static-methods。
- Spock 基于 Groovy,写出来的测试代码更清晰易读,比较规范(自带 given-when-then 的常用测试结构规范)。Mockito 没有具体的结构规范,需要项目组自己约定一个或者遵守比较好的测试代码实践。通常来说,同样的测试用例,Spock 的代码要更简洁。
- Mockito 使用的人群更广泛,稳定可靠。并且,Mockito 是 SpringBoot Test 默认集成的 Mock 工具。
Mockito 和 Spock 都是非常不错的 Mock 工具,相对来说,Mockito 的适用性更强一些。
总结
单元测试确实会带给你相当多的好处,但不是立刻体验出来。正如买重疾保险,交了很多保费,没病没痛,十几年甚至几十年都用不上,最好就是一辈子用不上理赔,身体健康最重要。单元测试也一样,写了可以买个放心,对代码的一种保障,有 bug 尽快测出来,没 bug 就最好,总不能说“写那么多单元测试,结果测不出 bug,浪费时间”吧?
以下是个人对单元测试一些建议:
- 越重要的代码,越要写单元测试;
- 代码做不到单元测试,多思考如何改进,而不是放弃;
- 边写业务代码,边写单元测试,而不是完成整个新功能后再写;
- 多思考如何改进、简化测试代码。
- 测试代码需要随着生产代码的演进而重构或者修改,如果测试不能保持整洁,只会越来越难修改。
作为一名经验丰富的程序员,写单元测试更多的是对自己的代码负责。有测试用例的代码,别人更容易看懂,以后别人接手你的代码时,也可能放心做改动。
多敲代码实践,多跟有单元测试经验的工程师交流,你会发现写单元测试获得的收益会更多。
Java 定时任务详解
为什么需要定时任务?
我们来看一下几个非常常见的业务场景:
- 某系统凌晨要进行数据备份。
- 某媒体聚合平台,每 10 分钟动态抓取某某网站的数据为自己所用。
- 某基金平台,每晚定时计算用户当日收益情况并推送给用户最新的数据。
这些场景往往都要求我们在某个特定的时间去做某个事情。
单机定时任务技术选型
Timer
java.util.Timer是 JDK 1.3 开始就已经支持的一种定时任务的实现方式。
Timer 内部使用一个叫做 TaskQueue 的类存放定时任务,它是一个基于最小堆实现的优先级队列。TaskQueue 会按照任务距离下一次执行时间的大小将任务排序,保证在堆顶的任务最先执行。这样在需要执行任务时,每次只需要取出堆顶的任务运行即可!
Timer 使用起来比较简单,通过下面的方式我们就能创建一个 1s 之后执行的定时任务。
|
|
不过其缺陷较多,比如一个 Timer 一个线程,这就导致 Timer 的任务的执行只能串行执行,一个任务执行时间过长的话会影响其他任务(性能非常差),再比如发生异常时任务直接停止(Timer 只捕获了 InterruptedException )。
Timer 类上的有一段注释是这样写的:
|
|
大概的意思就是:ScheduledThreadPoolExecutor 支持多线程执行定时任务并且功能更强大,是 Timer 的替代品。
ScheduledExecutorService
ScheduledExecutorService 是一个接口,有多个实现类,比较常用的是 ScheduledThreadPoolExecutor 。
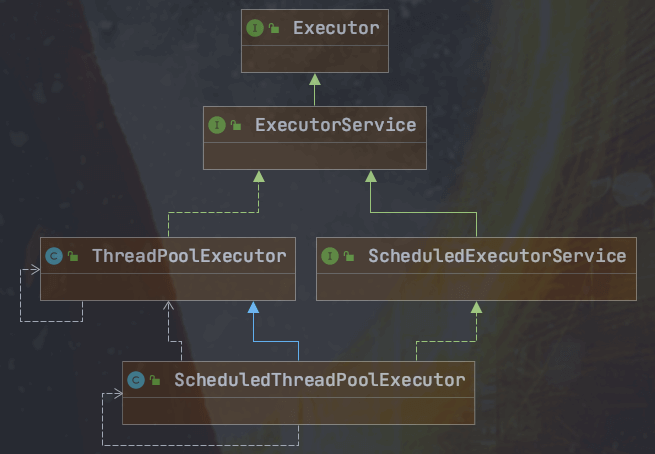
ScheduledThreadPoolExecutor 本身就是一个线程池,支持任务并发执行。并且,其内部使用 DelayedWorkQueue 作为任务队列。
|
|
不论是使用 Timer 还是 ScheduledExecutorService 都无法使用 Cron 表达式指定任务执行的具体时间。
Spring Task
我们直接通过 Spring 提供的 @Scheduled 注解即可定义定时任务,非常方便!
|
|
我在大学那会做的一个 SSM 的企业级项目,就是用的 Spring Task 来做的定时任务。
并且,Spring Task 还是支持 Cron 表达式 的。Cron 表达式主要用于定时作业(定时任务)系统定义执行时间或执行频率的表达式,非常厉害,你可以通过 Cron 表达式进行设置定时任务每天或者每个月什么时候执行等等操作。咱们要学习定时任务的话,Cron 表达式是一定是要重点关注的。推荐一个在线 Cron 表达式生成器:http://cron.qqe2.com/ 。
但是,Spring 自带的定时调度只支持单机,并且提供的功能比较单一。之前写过一篇文章:《5 分钟搞懂如何在 Spring Boot 中 Schedule Tasks》 ,不了解的小伙伴可以参考一下。
Spring Task 底层是基于 JDK 的 ScheduledThreadPoolExecutor 线程池来实现的。
优缺点总结:
- 优点:简单,轻量,支持 Cron 表达式
- 缺点:功能单一
时间轮
Kafka、Dubbo、ZooKeeper、Netty、Caffeine、Akka 中都有对时间轮的实现。
时间轮简单来说就是一个环形的队列(底层一般基于数组实现),队列中的每一个元素(时间格)都可以存放一个定时任务列表。
时间轮中的每个时间格代表了时间轮的基本时间跨度或者说时间精度,假如时间一秒走一个时间格的话,那么这个时间轮的最高精度就是 1 秒(也就是说 3 s 和 3.9s 会在同一个时间格中)。
下图是一个有 12 个时间格的时间轮,转完一圈需要 12 s。当我们需要新建一个 3s 后执行的定时任务,只需要将定时任务放在下标为 3 的时间格中即可。当我们需要新建一个 9s 后执行的定时任务,只需要将定时任务放在下标为 9 的时间格中即可。
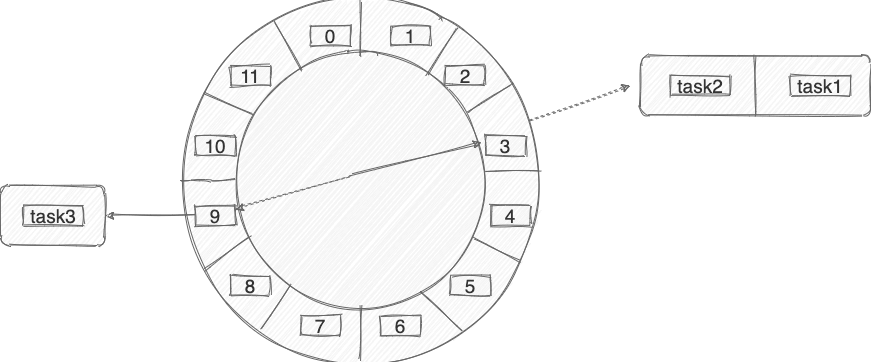
那当我们需要创建一个 13s 后执行的定时任务怎么办呢?这个时候可以引入一叫做 圈数/轮数 的概念,也就是说这个任务还是放在下标为 3 的时间格中, 不过它的圈数为 2 。
除了增加圈数这种方法之外,还有一种 多层次时间轮 (类似手表),Kafka 采用的就是这种方案。
针对下图的时间轮,我来举一个例子便于大家理解。
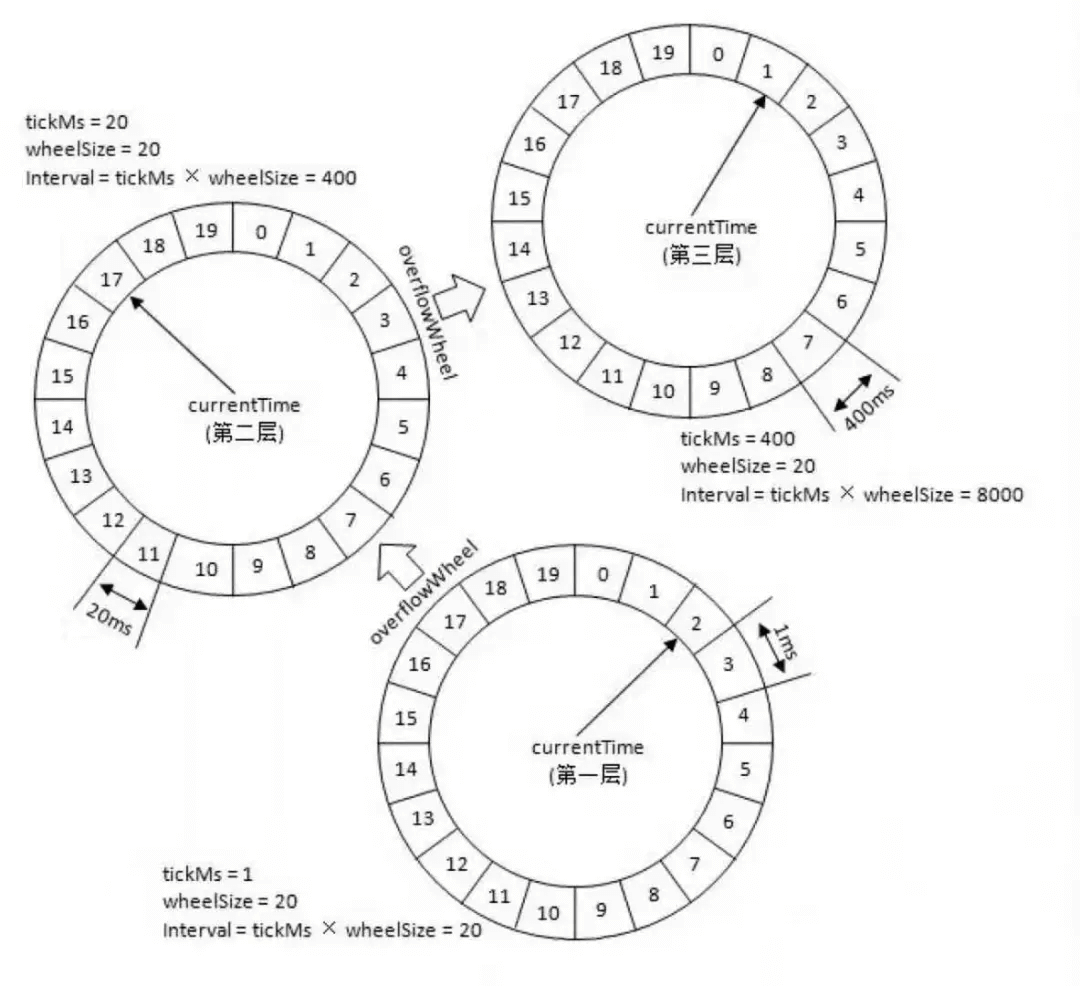
上图的时间轮,第 1 层的时间精度为 1 ,第 2 层的时间精度为 20 ,第 3 层的时间精度为 400。假如我们需要添加一个 350s 后执行的任务 A 的话(当前时间是 0s),这个任务会被放在第 2 层(因为第二层的时间跨度为 20*20=400>350)的第 350/20=17 个时间格子。
当第一层转了 17 圈之后,时间过去了 340s ,第 2 层的指针此时来到第 17 个时间格子。此时,第 2 层第 17 个格子的任务会被移动到第 1 层。
任务 A 当前是 10s 之后执行,因此它会被移动到第 1 层的第 10 个时间格子。
这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。
分布式定时任务技术选型
上面提到的一些定时任务的解决方案都是在单机下执行的,适用于比较简单的定时任务场景比如每天凌晨备份一次数据。
如果我们需要一些高级特性比如支持任务在分布式场景下的分片和高可用的话,我们就需要用到分布式任务调度框架了。
通常情况下,一个定时任务的执行往往涉及到下面这些角色:
- 任务:首先肯定是要执行的任务,这个任务就是具体的业务逻辑比如定时发送文章。
- 调度器:其次是调度中心,调度中心主要负责任务管理,会分配任务给执行器。
- 执行器:最后就是执行器,执行器接收调度器分派的任务并执行。
Quartz
一个很火的开源任务调度框架,完全由Java写成。Quartz 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 Quartz 开发的,比如当当网的elastic-job就是基于Quartz二次开发之后的分布式调度解决方案。
使用 Quartz 可以很方便地与 Spring集成,并且支持动态添加任务和集群。但是,Quartz 使用起来也比较麻烦,API 繁琐。
并且,Quartz 并没有内置 UI 管理控制台,不过你可以使用 quartzui 这个开源项目来解决这个问题。
另外,Quartz 虽然也支持分布式任务。但是,它是在数据库层面,通过数据库的锁机制做的,有非常多的弊端比如系统侵入性严重、节点负载不均衡。有点伪分布式的味道。
优缺点总结:
- 优点:可以与 Spring集成,并且支持动态添加任务和集群。
- 缺点:分布式支持不友好,没有内置 UI 管理控制台、使用麻烦(相比于其他同类型框架来说)
Elastic-Job
ElasticJob 当当网开源的一个面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。
ElasticJob-Lite 和 ElasticJob-Cloud 两者的对比如下:
| ElasticJob-Lite | ElasticJob-Cloud | |
|---|---|---|
| 无中心化 | 是 | 否 |
| 资源分配 | 不支持 | 支持 |
| 作业模式 | 常驻 | 常驻 + 瞬时 |
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
ElasticJob 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。

ElasticJob-Lite 的架构设计如下图所示:
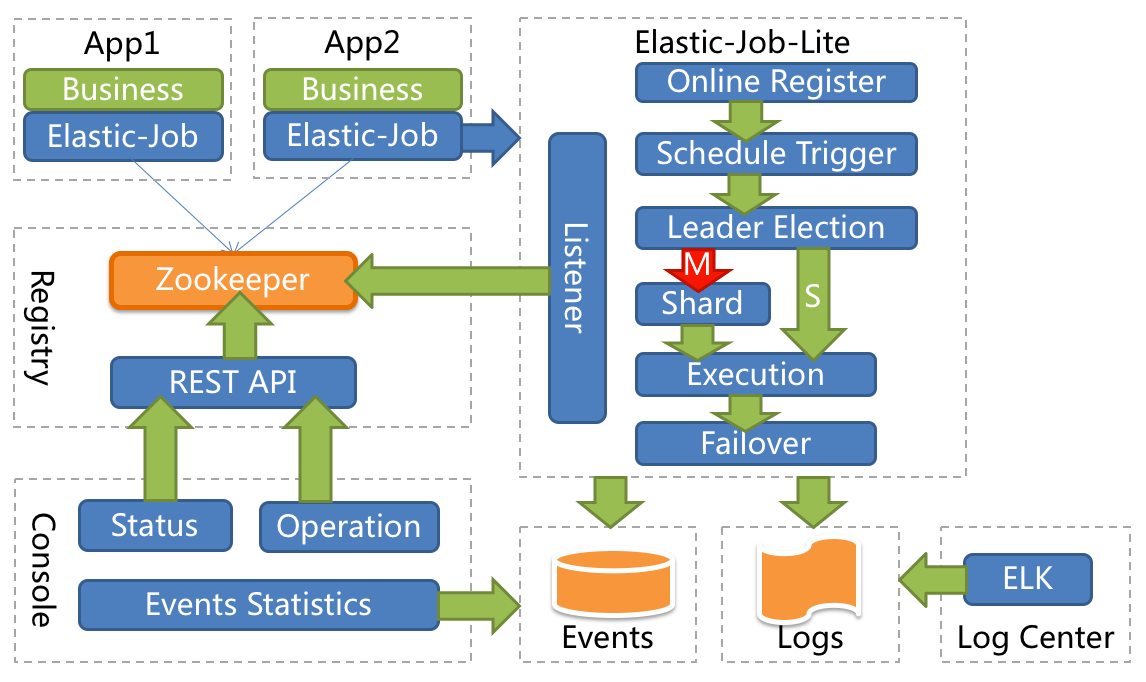
从上图可以看出,Elastic-Job没有调度中心这一概念,而是使用 ZooKeeper 作为注册中心,注册中心负责协调分配任务到不同的节点上。
Elastic-Job 中的定时调度都是由执行器自行触发,这种设计也被称为去中心化设计(调度和处理都是执行器单独完成)。
|
|
相关地址:
- GitHub 地址:https://github.com/apache/shardingsphere-elasticjob。
- 官方网站:https://shardingsphere.apache.org/elasticjob/index_zh.html 。
优缺点总结:
- 优点:可以与 Spring集成、支持分布式、支持集群、性能不错
- 缺点:依赖了额外的中间件比如 Zookeeper(复杂度增加,可靠性降低、维护成本变高)
XXL-JOB
XXL-JOB 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能,

根据 XXL-JOB 官网介绍,其解决了很多 Quartz 的不足。
Quartz作为开源作业调度中的佼佼者,是作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题:
- 问题一:调用API的的方式操作任务,不人性化;
- 问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
- 问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务;
- 问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务,充分发挥集群优势,负载各节点均衡。
XXL-JOB弥补了quartz的上述不足之处。
XXL-JOB 的架构设计如下图所示:
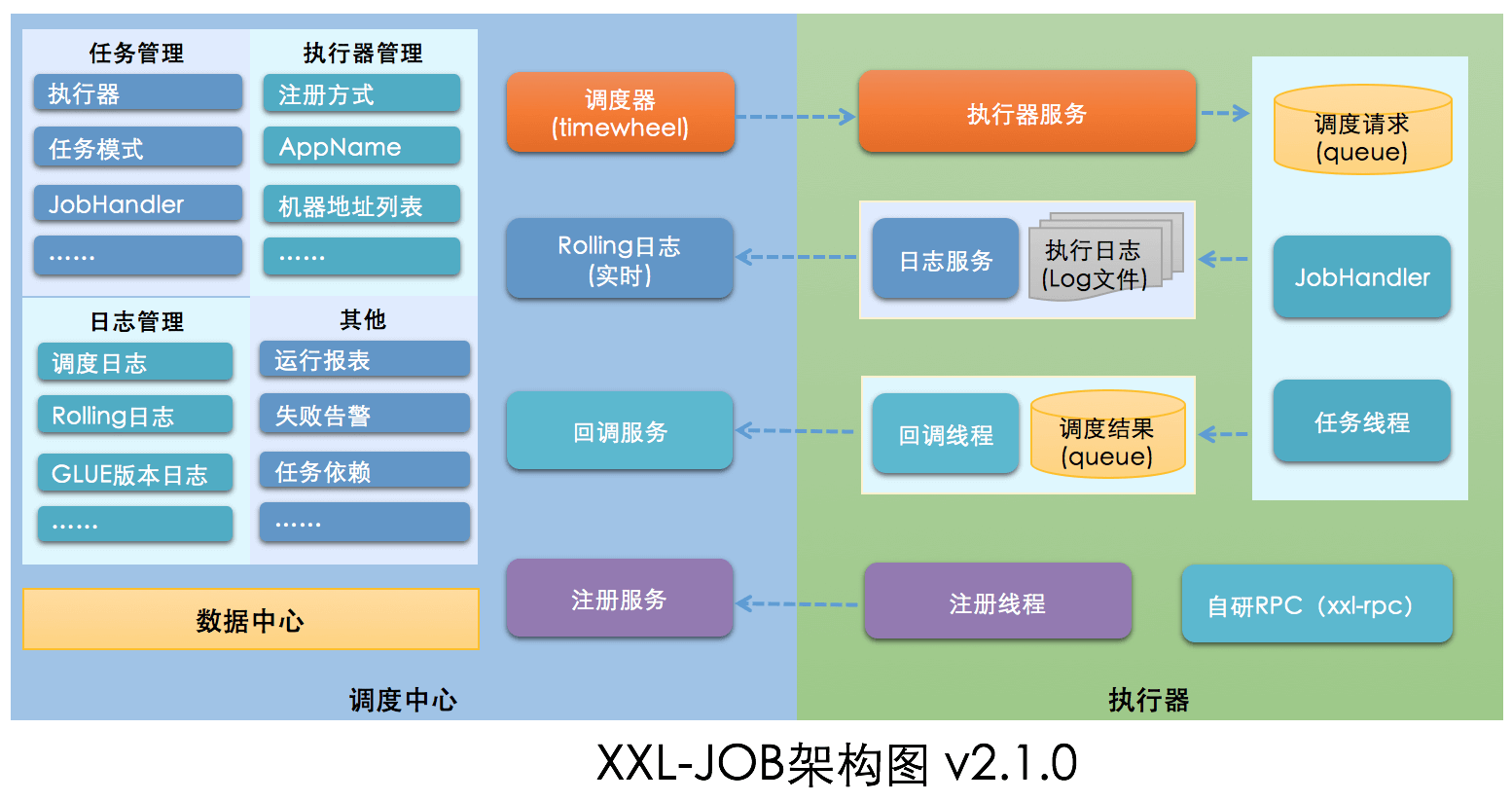
从上图可以看出,XXL-JOB 由 调度中心 和 执行器 两大部分组成。调度中心主要负责任务管理、执行器管理以及日志管理。执行器主要是接收调度信号并处理。另外,调度中心进行任务调度时,是通过自研 RPC 来实现的。
不同于 Elastic-Job的去中心化设计, XXL-JOB 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)。
和 Quzrtz 类似 XXL-JOB 也是基于数据库锁调度任务,存在性能瓶颈。不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。
不要被 XXL-JOB 的架构图给吓着了,实际上,我们要用 XXL-JOB 的话,只需要重写 IJobHandler 自定义任务执行逻辑就可以了,非常易用!
|
|
还可以直接基于注解定义任务。
|
|
相关地址:
- GitHub 地址:https://github.com/xuxueli/xxl-job/。
- 官方介绍:https://www.xuxueli.com/xxl-job/ 。
优缺点总结:
- 优点:开箱即用(学习成本比较低)、与 Spring 集成、支持分布式、支持集群、内置了 UI 管理控制台。
- 缺点:不支持动态添加任务(如果一定想要动态创建任务也是支持的,参见:xxl-job issue277)。
PowerJob
非常值得关注的一个分布式任务调度框架,分布式任务调度领域的新星。目前,已经有很多公司接入比如 OPPO、京东、中通、思科。
这个框架的诞生也挺有意思的,PowerJob 的作者当时在阿里巴巴实习过,阿里巴巴那会使用的是内部自研的 SchedulerX(阿里云付费产品)。实习期满之后,PowerJob 的作者离开了阿里巴巴。想着说自研一个 SchedulerX,防止哪天 SchedulerX 满足不了需求,于是 PowerJob 就诞生了。
更多关于 PowerJob 的故事,小伙伴们可以去看看 PowerJob 作者的视频 《我和我的任务调度中间件》。简单点概括就是:“游戏没啥意思了,我要扛起了新一代分布式任务调度与计算框架的大旗!”。
由于 SchedulerX 属于人民币产品,我这里就不过多介绍。PowerJob 官方也对比过其和 QuartZ、XXL-JOB 以及 SchedulerX。

总结
这篇文章中,我主要介绍了:
- 定时任务的相关概念:为什么需要定时任务、定时任务中的核心角色、分布式定时任务。
- 定时任务的技术选型:XXL-JOB 2015 年推出,已经经过了很多年的考验。XXL-JOB 轻量级,并且使用起来非常简单。虽然存在性能瓶颈,但是,在绝大多数情况下,对于企业的基本需求来说是没有影响的。PowerJob 属于分布式任务调度领域里的新星,其稳定性还有待继续考察。ElasticJob 由于在架构设计上是基于 Zookeeper ,而 XXL-JOB 是基于数据库,性能方面的话,ElasticJob 略胜一筹。
这篇文章并没有介绍到实际使用,但是,并不代表实际使用不重要。我在写这篇文章之前,已经动手写过相应的 Demo。像 Quartz,我在大学那会就用过。不过,当时用的是 Spring 。为了能够更好地体验,我自己又在 Spring Boot 上实际体验了一下。如果你并没有实际使用某个框架,就直接说它并不好用的话,是站不住脚的。
Web 实时消息推送详解
什么是消息推送?
推送的场景比较多,比如有人关注我的公众号,这时我就会收到一条推送消息,以此来吸引我点击打开应用。
消息推送通常是指网站的运营工作等人员,通过某种工具对用户当前网页或移动设备 APP 进行的主动消息推送。
消息推送一般又分为 Web 端消息推送和移动端消息推送。
移动端消息推送示例:

Web 端消息推送示例:

在具体实现之前,咱们再来分析一下前边的需求,其实功能很简单,只要触发某个事件(主动分享了资源或者后台主动推送消息),Web 页面的通知小红点就会实时的 +1 就可以了。
通常在服务端会有若干张消息推送表,用来记录用户触发不同事件所推送不同类型的消息,前端主动查询(拉)或者被动接收(推)用户所有未读的消息数。

消息推送无非是推(push)和拉(pull)两种形式,下边我们逐个了解下。
消息推送常见方案
短轮询
轮询(polling) 应该是实现消息推送方案中最简单的一种,这里我们暂且将轮询分为短轮询和长轮询。
短轮询很好理解,指定的时间间隔,由浏览器向服务器发出 HTTP 请求,服务器实时返回未读消息数据给客户端,浏览器再做渲染显示。
一个简单的 JS 定时器就可以搞定,每秒钟请求一次未读消息数接口,返回的数据展示即可。
|
|
效果还是可以的,短轮询实现固然简单,缺点也是显而易见,由于推送数据并不会频繁变更,无论后端此时是否有新的消息产生,客户端都会进行请求,势必会对服务端造成很大压力,浪费带宽和服务器资源。
长轮询
长轮询是对上边短轮询的一种改进版本,在尽可能减少对服务器资源浪费的同时,保证消息的相对实时性。长轮询在中间件中应用的很广泛,比如 Nacos 和 Apollo 配置中心,消息队列 Kafka、RocketMQ 中都有用到长轮询。
Nacos 配置中心交互模型是 push 还是 pull?一文中我详细介绍过 Nacos 长轮询的实现原理,感兴趣的小伙伴可以瞅瞅。
长轮询其实原理跟轮询差不多,都是采用轮询的方式。不过,如果服务端的数据没有发生变更,会 一直 hold 住请求,直到服务端的数据发生变化,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次长轮询。
这次我使用 Apollo 配置中心实现长轮询的方式,应用了一个类DeferredResult,它是在 Servlet3.0 后经过 Spring 封装提供的一种异步请求机制,直意就是延迟结果。
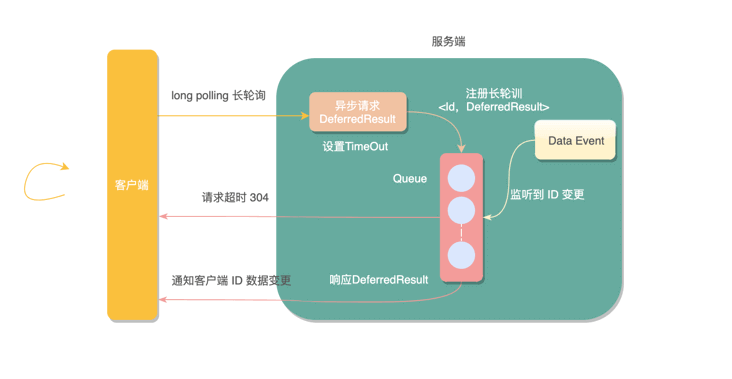
DeferredResult可以允许容器线程快速释放占用的资源,不阻塞请求线程,以此接受更多的请求提升系统的吞吐量,然后启动异步工作线程处理真正的业务逻辑,处理完成调用DeferredResult.setResult(200)提交响应结果。
下边我们用长轮询来实现消息推送。
因为一个 ID 可能会被多个长轮询请求监听,所以我采用了 Guava 包提供的Multimap结构存放长轮询,一个 key 可以对应多个 value。一旦监听到 key 发生变化,对应的所有长轮询都会响应。前端得到非请求超时的状态码,知晓数据变更,主动查询未读消息数接口,更新页面数据。
|
|
当请求超过设置的超时时间,会抛出AsyncRequestTimeoutException异常,这里直接用@ControllerAdvice全局捕获统一返回即可,前端获取约定好的状态码后再次发起长轮询请求,如此往复调用。
|
|
我们来测试一下,首先页面发起长轮询请求/polling/watch/10086监听消息更变,请求被挂起,不变更数据直至超时,再次发起了长轮询请求;紧接着手动变更数据/polling/publish/10086,长轮询得到响应,前端处理业务逻辑完成后再次发起请求,如此循环往复。
长轮询相比于短轮询在性能上提升了很多,但依然会产生较多的请求,这是它的一点不完美的地方。
iframe 流
iframe 流就是在页面中插入一个隐藏的<iframe>标签,通过在src中请求消息数量 API 接口,由此在服务端和客户端之间创建一条长连接,服务端持续向iframe传输数据。
传输的数据通常是 HTML、或是内嵌的 JavaScript 脚本,来达到实时更新页面的效果。
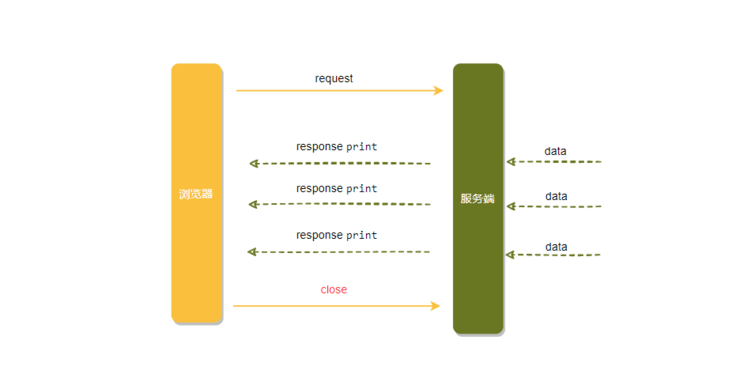
这种方式实现简单,前端只要一个<iframe>标签搞定了
|
|
服务端直接组装 HTML、JS 脚本数据向 response 写入就行了
|
|
iframe 流的服务器开销很大,而且 IE、Chrome 等浏览器一直会处于 loading 状态,图标会不停旋转,简直是强迫症杀手。
iframe 流非常不友好,强烈不推荐。
SSE
很多人可能不知道,服务端向客户端推送消息,其实除了可以用WebSocket这种耳熟能详的机制外,还有一种服务器发送事件(Server-Sent Events),简称 SSE。这是一种服务器端到客户端(浏览器)的单向消息推送。
SSE 基于 HTTP 协议的,我们知道一般意义上的 HTTP 协议是无法做到服务端主动向客户端推送消息的,但 SSE 是个例外,它变换了一种思路。
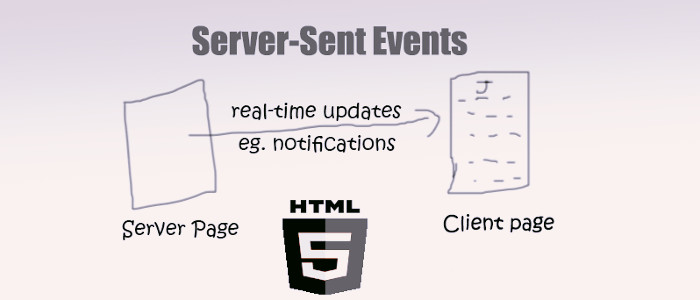
SSE 在服务器和客户端之间打开一个单向通道,服务端响应的不再是一次性的数据包而是text/event-stream类型的数据流信息,在有数据变更时从服务器流式传输到客户端。
整体的实现思路有点类似于在线视频播放,视频流会连续不断的推送到浏览器,你也可以理解成,客户端在完成一次用时很长(网络不畅)的下载。
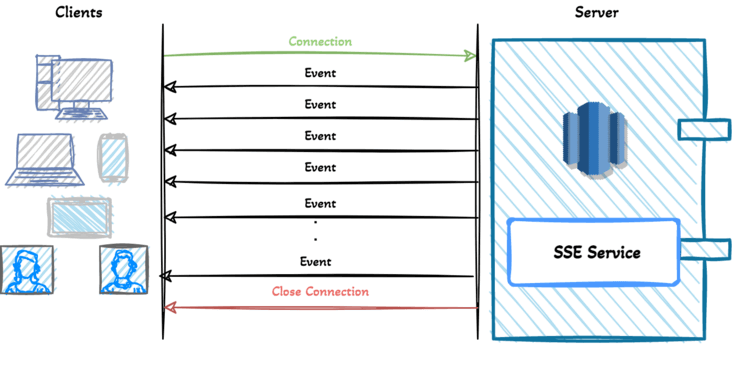
SSE 与 WebSocket 作用相似,都可以建立服务端与浏览器之间的通信,实现服务端向客户端推送消息,但还是有些许不同:
- SSE 是基于 HTTP 协议的,它们不需要特殊的协议或服务器实现即可工作;WebSocket 需单独服务器来处理协议。
- SSE 单向通信,只能由服务端向客户端单向通信;WebSocket 全双工通信,即通信的双方可以同时发送和接受信息。
- SSE 实现简单开发成本低,无需引入其他组件;WebSocket 传输数据需做二次解析,开发门槛高一些。
- SSE 默认支持断线重连;WebSocket 则需要自己实现。
- SSE 只能传送文本消息,二进制数据需要经过编码后传送;WebSocket 默认支持传送二进制数据。
SSE 与 WebSocket 该如何选择?
技术并没有好坏之分,只有哪个更合适
SSE 好像一直不被大家所熟知,一部分原因是出现了 WebSocket,这个提供了更丰富的协议来执行双向、全双工通信。对于游戏、即时通信以及需要双向近乎实时更新的场景,拥有双向通道更具吸引力。
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SEE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
前端只需进行一次 HTTP 请求,带上唯一 ID,打开事件流,监听服务端推送的事件就可以了
|
|
服务端的实现更简单,创建一个SseEmitter对象放入sseEmitterMap进行管理
|
|
注意: SSE 不支持 IE 浏览器,对其他主流浏览器兼容性做的还不错。

Websocket
Websocket 应该是大家都比较熟悉的一种实现消息推送的方式,上边我们在讲 SSE 的时候也和 Websocket 进行过比较。
是一种在 TCP 连接上进行全双工通信的协议,建立客户端和服务器之间的通信渠道。浏览器和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
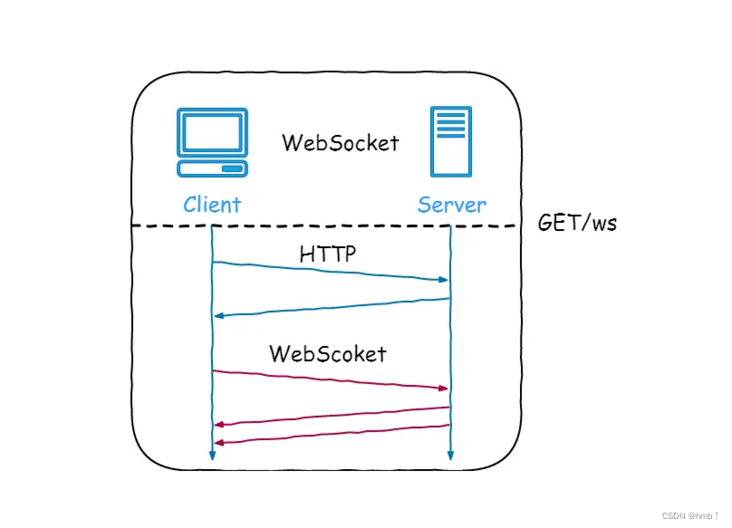
SpringBoot 整合 Websocket,先引入 Websocket 相关的工具包,和 SSE 相比额外的开发成本。
|
|
服务端使用@ServerEndpoint注解标注当前类为一个 WebSocket 服务器,客户端可以通过ws://localhost:7777/webSocket/10086来连接到 WebSocket 服务器端。
|
|
前端初始化打开 WebSocket 连接,并监听连接状态,接收服务端数据或向服务端发送数据。
|
|
页面初始化建立 WebSocket 连接,之后就可以进行双向通信了,效果还不错。

MQTT
什么是 MQTT 协议?
MQTT (Message Queue Telemetry Transport)是一种基于发布/订阅(publish/subscribe)模式的轻量级通讯协议,通过订阅相应的主题来获取消息,是物联网(Internet of Thing)中的一个标准传输协议。
该协议将消息的发布者(publisher)与订阅者(subscriber)进行分离,因此可以在不可靠的网络环境中,为远程连接的设备提供可靠的消息服务,使用方式与传统的 MQ 有点类似。
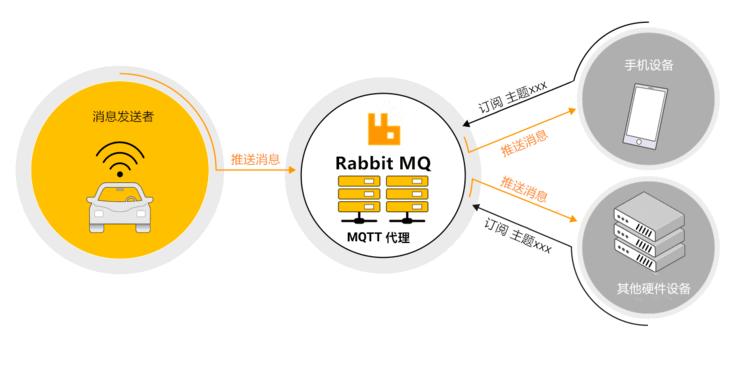
TCP 协议位于传输层,MQTT 协议位于应用层,MQTT 协议构建于 TCP/IP 协议上,也就是说只要支持 TCP/IP 协议栈的地方,都可以使用 MQTT 协议。
为什么要用 MQTT 协议?
MQTT 协议为什么在物联网(IOT)中如此受偏爱?而不是其它协议,比如我们更为熟悉的 HTTP 协议呢?
- 首先 HTTP 协议它是一种同步协议,客户端请求后需要等待服务器的响应。而在物联网(IOT)环境中,设备会很受制于环境的影响,比如带宽低、网络延迟高、网络通信不稳定等,显然异步消息协议更为适合 IOT 应用程序。
- HTTP 是单向的,如果要获取消息客户端必须发起连接,而在物联网(IOT)应用程序中,设备或传感器往往都是客户端,这意味着它们无法被动地接收来自网络的命令。
- 通常需要将一条命令或者消息,发送到网络上的所有设备上。HTTP 要实现这样的功能不但很困难,而且成本极高。
具体的 MQTT 协议介绍和实践,这里我就不再赘述了,大家可以参考我之前的两篇文章,里边写的也都很详细了。
- MQTT 协议的介绍:我也没想到 SpringBoot + RabbitMQ 做智能家居,会这么简单
- MQTT 实现消息推送:未读消息(小红点),前端 与 RabbitMQ 实时消息推送实践,贼简单~
总结
| 介绍 | 优点 | 缺点 | |
|---|---|---|---|
| 短轮询 | 客户端定时向服务端发送请求,服务端直接返回响应数据(即使没有数据更新) | 简单、易理解、易实现 | 实时性太差,无效请求太多,频繁建立连接太耗费资源 |
| 长轮询 | 与短轮询不同是,长轮询接收到客户端请求之后等到有数据更新才返回请求 | 减少了无效请求 | 挂起请求会导致资源浪费 |
| iframe 流 | 服务端和客户端之间创建一条长连接,服务端持续向iframe传输数据。 |
简单、易理解、易实现 | 维护一个长连接会增加开销,效果太差(图标会不停旋转) |
| SSE | 一种服务器端到客户端(浏览器)的单向消息推送。 | 简单、易实现,功能丰富 | 不支持双向通信 |
| WebSocket | 除了最初建立连接时用 HTTP 协议,其他时候都是直接基于 TCP 协议进行通信的,可以实现客户端和服务端的全双工通信。 | 性能高、开销小 | 对开发人员要求更高,实现相对复杂一些 |
| MQTT | 基于发布/订阅(publish/subscribe)模式的轻量级通讯协议,通过订阅相应的主题来获取消息。 | 成熟稳定,轻量级 | 对开发人员要求更高,实现相对复杂一些 |