概述
什么是集合(Collection)?集合就是“由若干个确定的元素所构成的整体”。例如,5只小兔构成的集合:
|
|
在数学中,我们经常遇到集合的概念。例如:
- 有限集合:
- 一个班所有的同学构成的集合;
- 一个网站所有的商品构成的集合;
- …
- 无限集合:
- 全体自然数集合:1,2,3,……
- 有理数集合;
- 实数集合;
- …
为什么要在计算机中引入集合呢?这是为了便于处理一组类似的数据,例如:
- 计算所有同学的总成绩和平均成绩;
- 列举所有的商品名称和价格;
- ……
在Java中,如果一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java的数组可以看作是一种集合:
|
|
既然Java提供了数组这种数据类型,可以充当集合,那么,我们为什么还需要其他集合类?这是因为数组有如下限制:
- 数组初始化后大小不可变;
- 数组只能按索引顺序存取。
因此,我们需要各种不同类型的集合类来处理不同的数据,例如:
- 可变大小的顺序链表;
- 保证无重复元素的集合;
- …
Collection
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
Java集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是List,具体的实现类有ArrayList,LinkedList等,二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
|
|
最后,Java访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
Hashtable:一种线程安全的Map实现;Vector:一种线程安全的List实现;Stack:基于Vector实现的LIFO的栈。
还有一小部分接口是遗留接口,也不应该继续使用:
Enumeration<E>:已被Iterator<E>取代。
使用Iterator
Java的集合类都可以使用for each循环,List、Set和Queue会迭代每个元素,Map会迭代每个key。以List为例:
|
|
实际上,Java编译器并不知道如何遍历List。上述代码能够编译通过,只是因为编译器把for each循环通过Iterator改写为了普通的for循环:
|
|
我们把这种通过Iterator对象遍历集合的模式称为迭代器。
使用迭代器的好处在于,调用方总是以统一的方式遍历各种集合类型,而不必关系它们内部的存储结构。
例如,我们虽然知道ArrayList在内部是以数组形式存储元素,并且,它还提供了get(int)方法。虽然我们可以用for循环遍历:
|
|
但是这样一来,调用方就必须知道集合的内部存储结构。并且,如果把ArrayList换成LinkedList,get(int)方法耗时会随着index的增加而增加。如果把ArrayList换成Set,上述代码就无法编译,因为Set内部没有索引。
用Iterator遍历就没有上述问题,因为Iterator对象是集合对象自己在内部创建的,它自己知道如何高效遍历内部的数据集合,调用方则获得了统一的代码,编译器才能把标准的for each循环自动转换为Iterator遍历。
如果我们自己编写了一个集合类,想要使用for each循环,只需满足以下条件:
- 集合类实现
Iterable接口,该接口要求返回一个Iterator对象; - 用
Iterator对象迭代集合内部数据。
这里的关键在于,集合类通过调用iterator()方法,返回一个Iterator对象,这个对象必须自己知道如何遍历该集合。
一个简单的Iterator示例如下,它总是以倒序遍历集合:
|
|
虽然ReverseList和ReverseIterator的实现类稍微比较复杂,但是,注意到这是底层集合库,只需编写一次。而调用方则完全按for each循环编写代码,根本不需要知道集合内部的存储逻辑和遍历逻辑。
在编写Iterator的时候,我们通常可以用一个内部类来实现Iterator接口,这个内部类可以直接访问对应的外部类的所有字段和方法。例如,上述代码中,内部类ReverseIterator可以用ReverseList.this获得当前外部类的this引用,然后,通过这个this引用就可以访问ReverseList的所有字段和方法。
小结
Iterator是一种抽象的数据访问模型。使用Iterator模式进行迭代的好处有:
- 对任何集合都采用同一种访问模型;
- 调用者对集合内部结构一无所知;
- 集合类返回的
Iterator对象知道如何迭代。
Java提供了标准的迭代器模型,即集合类实现java.util.Iterable接口,返回java.util.Iterator实例。
使用Collections
Collections是JDK提供的工具类,同样位于java.util包中。它提供了一系列静态方法,能更方便地操作各种集合。
注意:Collections结尾多了一个s,不是Collection!
我们一般看方法名和参数就可以确认Collections提供的该方法的功能。例如,对于以下静态方法:
|
|
addAll()方法可以给一个Collection类型的集合添加若干元素。因为方法签名是Collection,所以我们可以传入List,Set等各种集合类型。
创建空集合
Collections提供了一系列方法来创建空集合:
- 创建空List:
List<T> emptyList() - 创建空Map:
Map<K, V> emptyMap() - 创建空Set:
Set<T> emptySet()
要注意到返回的空集合是不可变集合,无法向其中添加或删除元素。
新版的JDK≥9可以直接使用List.of()、Map.of()、Set.of()来创建空集合。
创建单元素集合
Collections提供了一系列方法来创建一个单元素集合:
- 创建一个元素的List:
List<T> singletonList(T o) - 创建一个元素的Map:
Map<K, V> singletonMap(K key, V value) - 创建一个元素的Set:
Set<T> singleton(T o)
要注意到返回的单元素集合也是不可变集合,无法向其中添加或删除元素。
此外,也可以用各个集合接口提供的of(T...)方法创建单元素集合。例如,以下创建单元素List的两个方法是等价的:
|
|
实际上,使用List.of(T...)更方便,因为它既可以创建空集合,也可以创建单元素集合,还可以创建任意个元素的集合:
|
|
排序
Collections可以对List进行排序。因为排序会直接修改List元素的位置,因此必须传入可变List:
|
|
洗牌
Collections提供了洗牌算法,即传入一个有序的List,可以随机打乱List内部元素的顺序,效果相当于让计算机洗牌:
|
|
不可变集合
Collections还提供了一组方法把可变集合封装成不可变集合:
- 封装成不可变List:
List<T> unmodifiableList(List<? extends T> list) - 封装成不可变Set:
Set<T> unmodifiableSet(Set<? extends T> set) - 封装成不可变Map:
Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
这种封装实际上是通过创建一个代理对象,拦截掉所有修改方法实现的。我们来看看效果:
|
|
然而,继续对原始的可变List进行增删是可以的,并且,会直接影响到封装后的“不可变”List:
|
|
因此,如果我们希望把一个可变List封装成不可变List,那么,返回不可变List后,最好立刻扔掉可变List的引用,这样可以保证后续操作不会意外改变原始对象,从而造成“不可变”List变化了:
|
|
线程安全集合
Collections还提供了一组方法,可以把线程不安全的集合变为线程安全的集合:
- 变为线程安全的List:
List<T> synchronizedList(List<T> list) - 变为线程安全的Set:
Set<T> synchronizedSet(Set<T> s) - 变为线程安全的Map:
Map<K,V> synchronizedMap(Map<K,V> m)
多线程的概念我们会在后面讲。因为从Java 5开始,引入了更高效的并发集合类,所以上述这几个同步方法已经没有什么用了。
其他-总体框架
Java集合是java提供的工具包,包含了常用的数据结构:集合、链表、队列、栈、数组、映射等。Java集合工具包位置是java.util.*
Java集合主要可以划分为4个部分:List列表、Set集合、Map映射、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)、。
Java集合工具包框架图(如下):
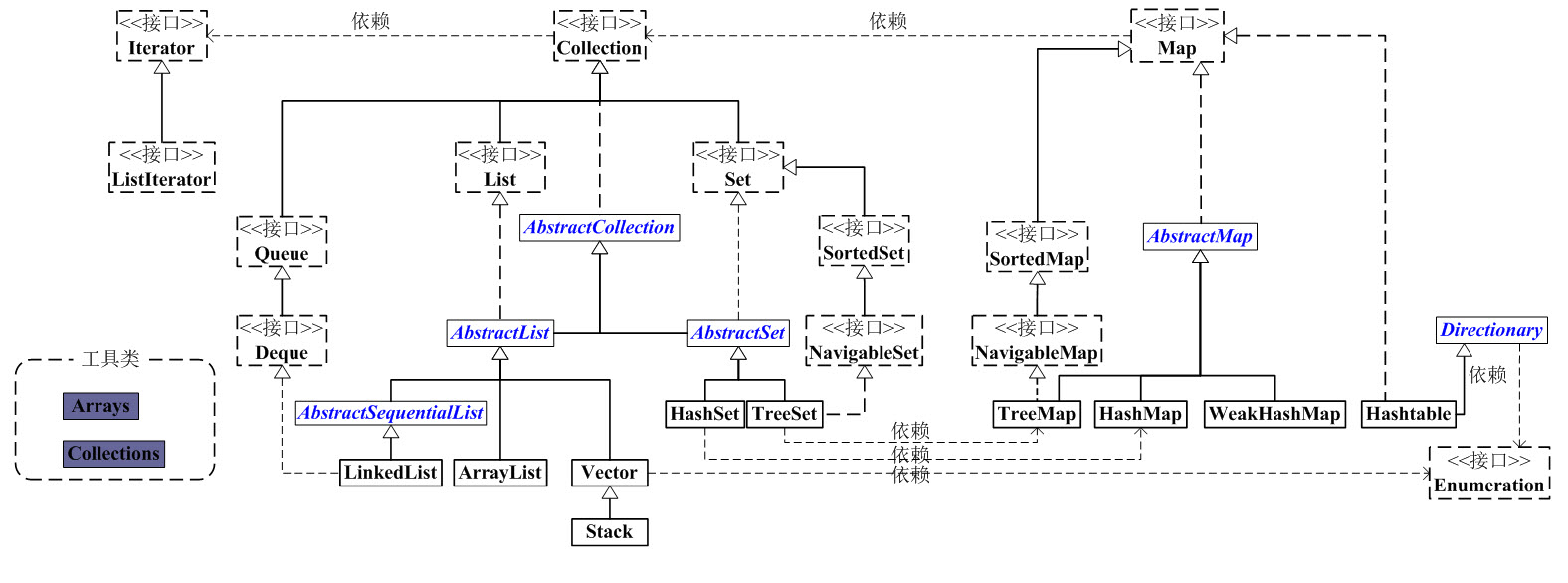
看上面的框架图,先抓住它的主干,即Collection和Map。
Collection
|
|
它是一个接口,是高度抽象出来的集合,它包含了集合的基本操作:添加、删除、清空、遍历(读取)、是否为空、获取大小、是否保护某元素等等。
Collection接口的所有子类(直接子类和间接子类)都必须实现2种构造函数:不带参数的构造函数 和 参数为Collection的构造函数。带参数的构造函数,可以用来转换Collection的类型。
Collection主要的两个分支是:List 和 Set。
List和Set都是接口,它们继承于Collection。
List是有序的队列,List中可以有重复的元素;
而Set是数学概念中的集合,Set中没有重复元素。
List和Set都有它们各自的实现类。
为了方便,我们抽象出了AbstractCollection抽象类,它实现了Collection中的绝大部分函数;这样,在Collection的实现类中,我们就可以通过继承AbstractCollection省去重复编码。
AbstractList和AbstractSet都继承于AbstractCollection,具体的List实现类继承于AbstractList,而Set的实现类则继承于AbstractSet。
另外,Collection中有一个iterator()函数,它的作用是返回一个Iterator接口。通常,我们通过Iterator迭代器来遍历集合。ListIterator是List接口所特有的,在List接口中,通过ListIterator()返回一个ListIterator对象。
为了方便对多个对象进行操作,集合是存储对象的最常用的一种方式。
集合的出现就是为了存储对象,可以存储任意类型的对象,而且长度可变。
集合和数组的区别?
- 都是容器
- 数组长度固定,集合长度可变
- 数组可以存储基本数据类型,集合只能存对象
- 数组存储的数据类型是单一的,集合可以存储任意类型的对象
AbstractCollection
定义如下:
|
|
AbstractCollection是一个抽象类,它实现了Collection中除iterator()和size()之外的函数。
主要作用:
它实现了Collection接口中的大部分函数。从而方便其它类实现Collection,比如ArrayList、LinkedList等,它们这些类想要实现Collection接口,通过继承AbstractCollection就已经实现了大部分的功能了。
List
定义如下:
|
|
List是一个继承于Collection的接口,即List是集合的一种。
List是有序的队列,List中的每一个元素都有一个索引;
第一个元素的索引值是0,往后的元素的索引值依次+1。
和Set不同,List中允许有重复的元素。
既然List是继承于Collection接口,它自然就包含了Collection中的全部函数接口;由于List是有序队列,它也额外的有自己的API接口。主要有“添加、删除、获取、修改指定位置的元素”、“获取List中的子队列”等。
Set
定义如下:
|
|
Set是一个继承于Collection的接口,即Set也是集合中的一种。Set是没有重复元素的集合。
Set的API和Collection完全一样。
AbstractList
定义如下:
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {}
AbstractList是一个继承于AbstractCollection,并且实现List接口的抽象类。它实现了List中除size()、get(int location)之外的函数。
AbstractList的主要作用:它实现了List接口中的大部分函数。从而方便其它类继承List。
另外,和AbstractCollection相比,AbstractList抽象类中,实现了iterator()接口。
AbstractSet
定义如下:
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {}
AbstractSet是一个继承于AbstractCollection,并且实现Set接口的抽象类。由于Set接口和Collection接口中的API完全一样,Set也就没有自己单独的API。和AbstractCollection一样,它实现了List中除iterator()和size()之外的函数。
AbstractSet的主要作用:它实现了Set接口中的大部分函数。从而方便其它类实现Set接口。
map
Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。
AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。
Hashtable虽然继承于Dictionary,但它实现了Map接口。
Enumeration
Enumeration是JDK 1.0引入的抽象类。作用和Iterator一样,也是遍历集合;但是Enumeration的功能要比Iterator少。在上面的框图中,Enumeration只能在Hashtable, Vector, Stack中使用。
Arrays和Collections
它们是操作数组、集合的两个工具类。
Iterator
Iterator是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。ListIterator是专门为遍历List而存在的。
public interface Iterator<E> {}
Iterator是一个接口,它是集合的迭代器。集合可以通过Iterator去遍历集合中的元素。Iterator提供的API接口,包括:
|
|
注意:Iterator遍历Collection时,是fail-fast机制的。即,当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。关于fail-fast的详细内容,我们会在后面专门进行说明。
实现了Iterable接口,就可以调用iterator()方法。
HashMap类就实现了Iterable接口,遍历map
|
|
手动迭代list,和foreach原理是一样的
|
|
AbstractList中实现的迭代器类解读
|
|
迭代出来的元素都是原来集合元素的拷贝
Java集合中保存的元素实质是对象的引用(可以理解为C中的指针),而非对象本身。迭代出的元素也就都是引用的拷贝,结果还是引用。那么,如果集合中保存的元素是可变类型的,我们就可以通过迭代出的元素修改原集合中的对象。而对于不可变类型,如String 基本元素的包装类型Integer 都是则不会反应到原集合中。验证:
|
|
自己实现迭代器
|
|
Iterable
|
|
Iterable是一个接口,Collection接口继承了Iterable(接口扩展),Iterable中包含
- iterator方法的显式调用
- forEach方法
- spliterator方法
Iterator和Iterable 区别
从英文意思去理解:
Iterable:故名思议,实现了这个接口的集合对象支持迭代,是可迭代的。
able结尾的表示**能...样**,**可以做...**
Iterator:在英语中or 结尾是都是表示**...样的人** 或 **... 者**。
如creator就是创作者的意思。这里也是一样:iterator就是迭代者,我们一般叫迭代器,它就是提供迭代机制的对象,具体如何迭代,都是Iterator接口规范的。
Iterable
一个集合对象要表明自己支持迭代,能有使用foreach语句的特权,就必须实现Iterable接口,表明我是可迭代的,然而实现Iterable接口,就必需为foreach语句提供一个迭代器。
这个迭代器是用接口定义的 iterator方法提供的。也就是iterator方法需要返回一个Iterator对象。
Iterator
- 每次在迭代前,先调用hasNext()探测是否迭代到终点(本次还能再迭代吗?)。
- next方法不仅要返回当前元素,还要后移游标cursor
- remove()方法用来删除最近一次已经迭代出的元素
- 迭代出的元素是原集合中元素的拷贝(重要)
- 配合foreach使用
为什么一定要实现Iterable接口,为什么不直接实现Iterator接口呢?
答:看一下JDK中的集合类,比如List一族或者Set一族,都是实现了Iterable接口,但并不直接实现Iterator接口。 仔细想一下这么做是有道理的。
因为Iterator接口的核心方法next()或者hasNext() 是依赖于迭代器的当前迭代位置的。 如果Collection直接实现Iterator接口,势必导致集合对象中包含当前迭代位置的数据(指针)。
当集合在不同方法间被传递时,由于当前迭代位置不可预置,那么next()方法的结果会变成不可预知。 除非再为Iterator接口添加一个reset()方法,用来重置当前迭代位置。
但即时这样,Collection也只能同时存在一个当前迭代位置。 而Iterable则不然,每次调用都会返回一个从头开始计数的迭代器。 多个迭代器是互不干扰的。
ListIterator
|
|
ListIterator是一个的接口,继承了Iterator,它是队列迭代器。专门用于遍历List,能提供向前/向后遍历。相比于Iterator,它新增了添加、是否存在上一个元素、获取上一个元素等等API接口。
ListIterator的API
|
|
其他-集合的特点
- 用于存储对象
- 长度可变
- 可以存储不同类型的对象
|
|
问题
list和set的区别
list允许重复对象,set不允许重复对象
list是有序容器,保留了每个元素的插入顺序,输出顺序就是插入顺序
set是无序容器,无法保证每个元素的存储顺序
list可以插入多个null元素,set只允许一个null元素
什么时候该使用什么样的集合:
- List:如果我们需要保留存储顺序, 并且保留重复元素, 使用List
- 如果查询较多, 那么使用ArrayList
- 如果存取较多, 那么使用LinkedList
- Set:如果我们不需要保留存储顺序, 并且需要去掉重复元素, 使用Set
- 如果我们需要将元素排序, 那么使用TreeSet
- 如果我们不需要排序, 使用HashSet, HashSet比TreeSet效率高
- 如果我们需要保留存储顺序,又要过滤重复元素,那么使用LinkedHashSet
用什么方法
看到array,就要想到角标。
看到link,就要想到first,last。
看到hash,就要想到hashCode,equals
看到tree,就要想到两个接口:Comparable,Comparator。
Collection接口的方法
- add():将指定对象存储到容器中
- addAll():直接添加一整个集合
- remove():将指定对象从集合中删除
- removeAll():直接删除一个集合
- clear():清空集合中的所有元素
- contains():判断集合中是否包含指定对象
- collection.size():返回集合的大小
- toArray():集合转换成数组
List特有的方法
- 增加:List.add(1,“指定元素”),在指定位置添加元素
- 删除:List.remove(1,“指定元素”),删除指定位置的元素
- 修改:List.set(1,“指定元素”),修改指定位置的元素
- 查找:List.get(1,“指定元素”),查找指定位置的元素
- 求子集合:
List<E> subList(int fromIndex, int toIndex) // 不包含toIndex
LinkedList特有方法
- addFirst():在集合的第一个位置添加元素
- addLast():最后
- getFirst():返回此集合的第一个元素
- getLast():最后
- removeFirst():移除集合的第一个元素
- removeLast():最后
其他-Iterator和Enumeration区别
在Java集合中,我们通常都通过 “Iterator(迭代器)” 或 “Enumeration(枚举类)” 去遍历集合。现在看一下它们之间到底有什么区别。
Enumeration是一个接口,它的源码如下:
|
|
Iterator也是一个接口,它的源码如下:
|
|
函数接口不同
Enumeration只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。
Iterator只有3个函数接口。Iterator除了能读取集合的数据之外,也能数据进行删除操作。
Iterator支持fail-fast机制,而Enumeration不支持。
Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK 1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。
而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
Iterator和Enumeration实例
下面,我们编写一个Hashtable,然后分别通过 Iterator 和 Enumeration 去遍历它,比较它们的效率。代码如下:
|
|
运行结果如下:
time: 9ms
time: 5ms
从中,我们可以看出。Enumeration 比 Iterator 的遍历速度更快。为什么呢?
这是因为,Hashtable中Iterator是通过Enumeration去实现的,而且Iterator添加了对fail-fast机制的支持;所以,执行的操作自然要多一些。