在集合类中,List是最基础的一种集合:它是一种有序列表。
List的行为和数组几乎完全相同:List内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List的索引和数组一样,从0开始。
数组和List类似,也是有序结构,如果我们使用数组,在添加和删除元素的时候,会非常不方便。例如,从一个已有的数组{'A', 'B', 'C', 'D', 'E'}中删除索引为2的元素:
1
2
3
4
5
6
7
8
9
10
11
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ E │ │
└───┴───┴───┴───┴───┴───┘
│ │
┌───┘ │
│ ┌───┘
│ │
▼ ▼
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ D │ E │ │ │
└───┴───┴───┴───┴───┴───┘
copy
这个“删除”操作实际上是把'C'后面的元素依次往前挪一个位置,而“添加”操作实际上是把指定位置以后的元素都依次向后挪一个位置,腾出来的位置给新加的元素。这两种操作,用数组实现非常麻烦。
因此,在实际应用中,需要增删元素的有序列表,我们使用最多的是ArrayList。实际上,ArrayList在内部使用了数组来存储所有元素。例如,一个ArrayList拥有5个元素,实际数组大小为6(即有一个空位):
1
2
3
4
size=5
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ E │ │
└───┴───┴───┴───┴───┴───┘
copy
当添加一个元素并指定索引到ArrayList时,ArrayList自动移动需要移动的元素:
1
2
3
4
size=5
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ │ C │ D │ E │
└───┴───┴───┴───┴───┴───┘
copy
然后,往内部指定索引的数组位置添加一个元素,然后把size加1:
1
2
3
4
size=6
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │
└───┴───┴───┴───┴───┴───┘
copy
继续添加元素,但是数组已满,没有空闲位置的时候,ArrayList先创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组:
1
2
3
4
size=6
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │ │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
copy
现在,新数组就有了空位,可以继续添加一个元素到数组末尾,同时size加1:
1
2
3
4
size=7
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │ G │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
copy
可见,ArrayList把添加和删除的操作封装起来,让我们操作List类似于操作数组,却不用关心内部元素如何移动。
我们考察List<E>接口,可以看到几个主要的接口方法:
在末尾添加一个元素:boolean add(E e)
在指定索引添加一个元素:boolean add(int index, E e)
删除指定索引的元素:E remove(int index)
删除某个元素:boolean remove(Object e)
获取指定索引的元素:E get(int index)
获取链表大小(包含元素的个数):int size()
但是,实现List接口并非只能通过数组(即ArrayList的实现方式)来实现,另一种LinkedList通过“链表”也实现了List接口。在LinkedList中,它的内部每个元素都指向下一个元素:
1
2
3
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
copy
我们来比较一下ArrayList和LinkedList:
ArrayList
LinkedList
获取指定元素
速度很快
需要从头开始查找元素
添加元素到末尾
速度很快
速度很快
在指定位置添加/删除
需要移动元素
不需要移动元素
内存占用
少
较大
通常情况下,我们总是优先使用ArrayList。
List的特点#
使用List时,我们要关注List接口的规范。List接口允许我们添加重复的元素,即List内部的元素可以重复:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add ("apple" ); // size=1
list.add ("pear" ); // size=2
list.add ("apple" ); // 允许重复添加元素,size=3
System.out .println (list.size ());
}
}
copy
List还允许添加null:
1
2
3
4
5
6
7
8
9
10
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add ("apple" ); // size=1
list.add (null ); // size=2
list.add ("pear" ); // size=3
String second = list.get (1); // null
System.out .println (second);
}
}
copy
创建List#
除了使用ArrayList和LinkedList,我们还可以通过List接口提供的of()方法,根据给定元素快速创建List:
1
List<Integer> list = List.of(1, 2, 5);
copy
但是List.of()方法不接受null值,如果传入null,会抛出NullPointerException异常。
遍历List#
和数组类型,我们要遍历一个List,完全可以用for循环根据索引配合get(int)方法遍历:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("apple" , "pear" , "banana" );
for (int i=0; i<list.size (); i++) {
String s = list.get (i);
System.out .println (s);
}
}
}
copy
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
所以我们要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
Iterator对象有两个方法:boolean hasNext()判断是否有下一个元素,E next()返回下一个元素。因此,使用Iterator遍历List代码如下:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("apple" , "pear" , "banana" );
for (Iterator<String> it = list.iterator (); it.hasNext (); ) {
String s = it.next ();
System.out .println (s);
}
}
}
copy
有童鞋可能觉得使用Iterator访问List的代码比使用索引更复杂。但是,要记住,通过Iterator遍历List永远是最高效的方式。并且,由于Iterator遍历是如此常用,所以,Java的for each循环本身就可以帮我们使用Iterator遍历。把上面的代码再改写如下:
1
2
3
4
5
6
7
8
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("apple" , "pear" , "banana" );
for (String s : list) {
System.out .println (s);
}
}
}
copy
上述代码就是我们编写遍历List的常见代码。
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator<E> iterator()方法,强迫集合类必须返回一个Iterator实例。
List和Array转换#
把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("apple" , "pear" , "banana" );
Object[] array = list.toArray ();
for (Object s : array) {
System.out .println (s);
}
}
}
copy
这种方法会丢失类型信息,所以实际应用很少。
第二种方式是给toArray(T[])传入一个类型相同的Array,List内部自动把元素复制到传入的Array中:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of (12, 34, 56);
Integer[] array = list.toArray (new Integer[3]);
for (Integer n : array) {
System.out .println (n);
}
}
}
copy
注意到这个toArray(T[])方法的泛型参数<T>并不是List接口定义的泛型参数<E>,所以,我们实际上可以传入其他类型的数组,例如我们传入Number类型的数组,返回的仍然是Number类型:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of (12, 34, 56);
Number[] array = list.toArray (new Number[3]);
for (Number n : array) {
System.out .println (n);
}
}
}
copy
但是,如果我们传入类型不匹配的数组,例如,String[]类型的数组,由于List的元素是Integer,所以无法放入String数组,这个方法会抛出ArrayStoreException。
如果我们传入的数组大小和List实际的元素个数不一致怎么办?根据List接口 的文档,我们可以知道:
如果传入的数组不够大,那么List内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比List元素还要多,那么填充完元素后,剩下的数组元素一律填充null。
实际上,最常用的是传入一个“恰好”大小的数组:
1
Integer[] array = list.toArray (new Integer[list.size ()]);
copy
最后一种更简洁的写法是通过List接口定义的T[] toArray(IntFunction<T[]> generator)方法:
1
Integer[] array = list.toArray (Integer[]::new );
copy
这种函数式写法我们会在后续讲到。
反过来,把Array变为List就简单多了,通过List.of(T...)方法最简单:
1
2
Integer[] array = { 1, 2, 3 };
List<Integer> list = List.of (array);
copy
对于JDK 11之前的版本,可以使用Arrays.asList(T...)方法把数组转换成List。
要注意的是,返回的List不一定就是ArrayList或者LinkedList,因为List只是一个接口,如果我们调用List.of(),它返回的是一个只读List:
1
2
3
4
5
6
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of (12, 34, 56);
list.add (999); // UnsupportedOperationException
}
}
copy
对只读List调用add()、remove()方法会抛出UnsupportedOperationException。
给定一组连续的整数,例如:10,11,12,……,20,但其中缺失一个数字,试找出缺失的数字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.util.*;
public class Main {
public static void main(String[] args) {
// 构造从start到end的序列:
final int start = 10;
final int end = 20;
List<Integer> list = new ArrayList<>();
for (int i = start; i <= end; i++) {
list.add (i);
}
// 随机删除List中的一个元素:
int removed = list.remove ((int ) (Math.random () * list.size ()));
int found = findMissingNumber(start, end, list);
System.out .println (list.toString ());
System.out .println ("missing number: " + found);
System.out .println (removed == found ? "测试成功" : "测试失败" );
}
static int findMissingNumber(int start, int end, List<Integer> list) {
return 0;
}
}
copy
增强版:和上述题目一样,但整数不再有序,试找出缺失的数字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import java.util.*;
public class Main {
public static void main(String[] args) {
// 构造从start到end的序列:
final int start = 10;
final int end = 20;
List<Integer> list = new ArrayList<>();
for (int i = start; i <= end; i++) {
list.add (i);
}
// 洗牌算法shuffle可以随机交换List中的元素位置:
Collections.shuffle (list);
// 随机删除List中的一个元素:
int removed = list.remove ((int ) (Math.random () * list.size ()));
int found = findMissingNumber(start, end, list);
System.out .println (list.toString ());
System.out .println ("missing number: " + found);
System.out .println (removed == found ? "测试成功" : "测试失败" );
}
static int findMissingNumber(int start, int end, List<Integer> list) {
return 0;
}
}
copy
编写equals()方法#
我们知道List是一种有序链表:List内部按照放入元素的先后顺序存放,并且每个元素都可以通过索引确定自己的位置。
List还提供了boolean contains(Object o)方法来判断List是否包含某个指定元素。此外,int indexOf(Object o)方法可以返回某个元素的索引,如果元素不存在,就返回-1。
我们来看一个例子:
1
2
3
4
5
6
7
8
9
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("A" , "B" , "C" );
System.out .println (list.contains ("C" )); // true
System.out .println (list.contains ("X" )); // false
System.out .println (list.indexOf ("C" )); // 2
System.out .println (list.indexOf ("X" )); // -1
}
}
copy
这里我们注意一个问题,我们往List中添加的"C"和调用contains("C")传入的"C"是不是同一个实例?
如果这两个"C"不是同一个实例,这段代码是否还能得到正确的结果?我们可以改写一下代码测试一下:
1
2
3
4
5
6
7
public class Main {
public static void main(String[] args) {
List<String> list = List.of ("A" , "B" , "C" );
System.out .println (list.contains (new String("C" ))); // true or false?
System.out .println (list.indexOf (new String("C" ))); // 2 or -1?
}
}
copy
因为我们传入的是new String("C"),所以一定是不同的实例。结果仍然符合预期,这是为什么呢?
因为List内部并不是通过==判断两个元素是否相等,而是使用equals()方法判断两个元素是否相等,例如contains()方法可以实现如下:
1
2
3
4
5
6
7
8
9
10
11
public class ArrayList {
Object[] elementData;
public boolean contains(Object o) {
for (int i = 0; i < elementData.length ; i++) {
if (o.equals (elementData[i])) {
return true ;
}
}
return false ;
}
}
copy
因此,要正确使用List的contains()、indexOf()这些方法,放入的实例必须正确覆写equals()方法,否则,放进去的实例,查找不到。我们之所以能正常放入String、Integer这些对象,是因为Java标准库定义的这些类已经正确实现了equals()方法。
我们以Person对象为例,测试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class Main {
public static void main(String[] args) {
List<Person> list = List.of (
new Person("Xiao Ming" ),
new Person("Xiao Hong" ),
new Person("Bob" )
);
System.out .println (list.contains (new Person("Bob" ))); // false
}
}
class Person {
String name;
public Person(String name) {
this .name = name;
}
}
copy
不出意外,虽然放入了new Person("Bob"),但是用另一个new Person("Bob")查询不到,原因就是Person类没有覆写equals()方法。
编写equals#
如何正确编写equals()方法?equals()方法要求我们必须满足以下条件:
自反性(Reflexive):对于非null的x来说,x.equals(x)必须返回true;
对称性(Symmetric):对于非null的x和y来说,如果x.equals(y)为true,则y.equals(x)也必须为true;
传递性(Transitive):对于非null的x、y和z来说,如果x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)也必须为true;
一致性(Consistent):对于非null的x和y来说,只要x和y状态不变,则x.equals(y)总是一致地返回true或者false;
对null的比较:即x.equals(null)永远返回false。
上述规则看上去似乎非常复杂,但其实代码实现equals()方法是很简单的,我们以Person类为例:
1
2
3
4
public class Person {
public String name;
public int age;
}
copy
首先,我们要定义“相等”的逻辑含义。对于Person类,如果name相等,并且age相等,我们就认为两个Person实例相等。
因此,编写equals()方法如下:
1
2
3
4
5
6
7
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return this .name .equals (p.name ) && this .age == p.age ;
}
return false ;
}
copy
对于引用字段比较,我们使用equals(),对于基本类型字段的比较,我们使用==。
如果this.name为null,那么equals()方法会报错,因此,需要继续改写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
boolean nameEquals = false ;
if (this .name == null && p.name == null ) {
nameEquals = true ;
}
if (this .name != null ) {
nameEquals = this .name .equals (p.name );
}
return nameEquals && this .age == p.age ;
}
return false ;
}
copy
如果Person有好几个引用类型的字段,上面的写法就太复杂了。要简化引用类型的比较,我们使用Objects.equals()静态方法:
1
2
3
4
5
6
7
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return Objects.equals (this .name , p.name ) && this .age == p.age ;
}
return false ;
}
copy
因此,我们总结一下equals()方法的正确编写方法:
先确定实例“相等”的逻辑,即哪些字段相等,就认为实例相等;
用instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false;
对引用类型用Objects.equals()比较,对基本类型直接用==比较。
使用Objects.equals()比较两个引用类型是否相等的目的是省去了判断null的麻烦。两个引用类型都是null时它们也是相等的。
如果不调用List的contains()、indexOf()这些方法,那么放入的元素就不需要实现equals()方法。
在List中查找元素时,List的实现类通过元素的equals()方法比较两个元素是否相等,因此,放入的元素必须正确覆写equals()方法,Java标准库提供的String、Integer等已经覆写了equals()方法;
编写equals()方法可借助Objects.equals()判断。
如果不在List中查找元素,就不必覆写equals()方法。
给Person类增加equals方法,使得调用indexOf()方法返回正常:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import java.util.List;
import java.util.Objects;
public class Main {
public static void main(String[] args) {
List<Person> list = List.of (
new Person("Xiao" , "Ming" , 18),
new Person("Xiao" , "Hong" , 25),
new Person("Bob" , "Smith" , 20)
);
boolean exist = list.contains (new Person("Bob" , "Smith" , 20));
System.out .println (exist ? "测试成功!" : "测试失败!" );
}
}
class Person {
String firstName;
String lastName;
int age;
public Person(String firstName, String lastName, int age) {
this .firstName = firstName;
this .lastName = lastName;
this .age = age;
}
}
copy
List概括#
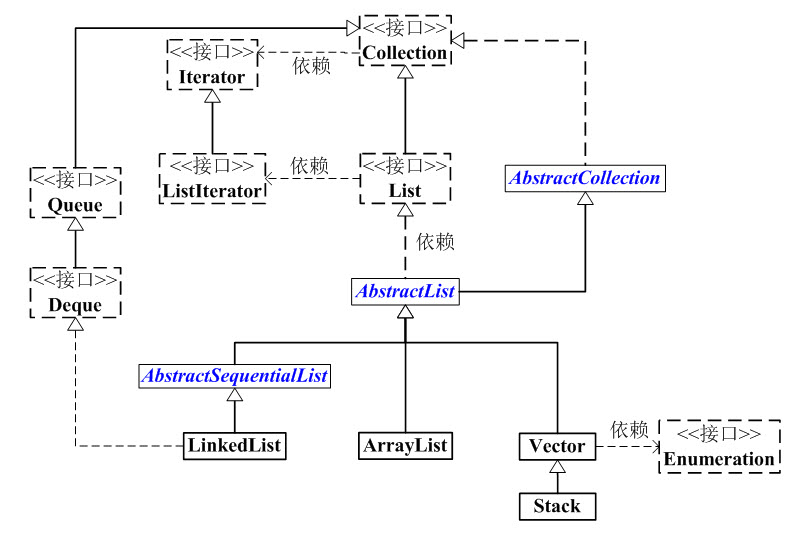
List的框架图
List是一个接口,继承于Collection接口,是线性数据结构的主要实现,集合元素通常存在明确的上一个和下一个元素,也存在明确的第一个元素和最后一个元素。
AbstractList是一个抽象类,继承于AbstractCollection。AbstractList实现List接口中除size()、get(int location)之外的函数。
AbstractSequentialList 是一个抽象类,它继承于AbstractList。AbstractSequentialList 实现了“链表中,根据index索引值操作链表的全部函数”。
ArrayList、LinkedList、Vector、Stack是List的4个实现类。
ArrayList 是容量可变的非线程安全集合。内部使用数组进行存储,集合扩容时会创建更大的数组空间,把原有数据复制到新数组中。ArrayList 支持对元素的快速随机访问,但是插入与删除时速度很慢,因为这个过程很有可能需要移动其他元素。
LinkedList 是一个双向链表,与 ArrayList 相比,LinkedList 的插入和删除速度更快,但是随机访问速度很慢。
Vector是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
Stack是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。
使用场景#
如果涉及到“栈”、“队列”、“链表”等操作,应该考虑用List,具体的选择哪个List,根据下面的标准来取舍。
对于需要快速插入,删除元素,应该使用LinkedList。
对于需要快速随机访问元素,应该使用ArrayList。
通过下面的测试程序,验证上面前两条结论:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
import java.util.*;
import java.lang.Class;
/*
* @desc 对比ArrayList和LinkedList的插入、随机读取效率、删除的效率
*/
public class ListCompareTest {
private static final int COUNT = 100000;
private static LinkedList linkedList = new LinkedList();
private static ArrayList arrayList = new ArrayList();
private static Vector vector = new Vector();
private static Stack stack = new Stack();
public static void main(String[] args) {
// 换行符
System.out .println ();
// 插入
insertByPosition(stack) ;
insertByPosition(vector) ;
insertByPosition(linkedList) ;
insertByPosition(arrayList) ;
// 换行符
System.out .println ();
// 随机读取
readByPosition(stack);
readByPosition(vector);
readByPosition(linkedList);
readByPosition(arrayList);
// 换行符
System.out .println ();
// 删除
deleteByPosition(stack);
deleteByPosition(vector);
deleteByPosition(linkedList);
deleteByPosition(arrayList);
}
// 获取list的名称
private static String getListName(List list) {
if (list instanceof LinkedList) {
return "LinkedList" ;
} else if (list instanceof ArrayList) {
return "ArrayList" ;
} else if (list instanceof Stack) {
return "Stack" ;
} else if (list instanceof Vector) {
return "Vector" ;
} else {
return "List" ;
}
}
// 向list的指定位置插入COUNT个元素,并统计时间
private static void insertByPosition(List list) {
long startTime = System.currentTimeMillis ();
// 向list的位置0插入COUNT个数
for (int i=0; i<COUNT; i++)
list.add (0, i);
long endTime = System.currentTimeMillis ();
long interval = endTime - startTime;
System.out .println (getListName(list) + " : insert " +COUNT+" elements into the 1st position use time:" + interval+" ms" );
}
// 从list的指定位置删除COUNT个元素,并统计时间
private static void deleteByPosition(List list) {
long startTime = System.currentTimeMillis ();
// 删除list第一个位置元素
for (int i=0; i<COUNT; i++)
list.remove (0);
long endTime = System.currentTimeMillis ();
long interval = endTime - startTime;
System.out .println (getListName(list) + " : delete " +COUNT+" elements from the 1st position use time:" + interval+" ms" );
}
// 根据position,不断从list中读取元素,并统计时间
private static void readByPosition(List list) {
long startTime = System.currentTimeMillis ();
// 读取list元素
for (int i=0; i<COUNT; i++)
list.get (i);
long endTime = System.currentTimeMillis ();
long interval = endTime - startTime;
System.out .println (getListName(list) + " : read " +COUNT+" elements by position use time:" + interval+" ms" );
}
}
copy
运行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Stack : insert 100000 elements into the 1st position use time:1640 ms
Vector : insert 100000 elements into the 1st position use time:1607 ms
LinkedList : insert 100000 elements into the 1st position use time:29 ms
ArrayList : insert 100000 elements into the 1st position use time:1617 ms
Stack : read 100000 elements by position use time:9 ms
Vector : read 100000 elements by position use time:6 ms
LinkedList : read 100000 elements by position use time:10809 ms
ArrayList : read 100000 elements by position use time:5 ms
Stack : delete 100000 elements from the 1st position use time:1916 ms
Vector : delete 100000 elements from the 1st position use time:1910 ms
LinkedList : delete 100000 elements from the 1st position use time:15 ms
ArrayList : delete 100000 elements from the 1st position use time:1909 ms
copy
从中,我们可以发现:
考虑到Vector是支持同步的,而Stack又是继承于Vector的;因此,得出结论:
LinkedList和ArrayList性能差异分析#
通过查看源码,看看为什么LinkedList插入元素快,ArrayList插入慢。
LinkedList.java中向指定位置插入元素的代码如下#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 在index前添加节点,且节点的值为element
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: " +index+", Size: " +size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前向后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next ;
} else {
for (int i = size; i > index; i--)
e = e.previous ;
}
return e;
}
// 将节点(节点数据是e)添加到entry节点之前。
private Entry<E> addBefore(E e, Entry<E> entry) {
// 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous );
// 插入newEntry到链表中
newEntry.previous .next = newEntry;
newEntry.next .previous = newEntry;
size++;
modCount++;
return newEntry;
}
copy
从中,我们可以看出:通过add(int index, E element)向LinkedList插入元素时。先是在双向链表中找到要插入节点的位置index;找到之后,再插入一个新节点。双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找;否则,从后向前查找。
ArrayList.java中向指定位置插入元素的代码。如下:#
1
2
3
4
5
6
7
8
9
10
11
12
// 将e添加到ArrayList的指定位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " +index+", Size: " +size);
ensureCapacity(size+1); // Increments modCount!!
System.arraycopy (elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
copy
ensureCapacity(size+1)
1
System.arraycopy (elementData, index, elementData, index + 1, size - index);
copy
Sun JDK包的java/lang/System.java中的arraycopy()声明如下:
1
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
copy
arraycopy()是个JNI函数,它是在JVM中实现的。Sun JDK中看不到源码,不过可以在OpenJDK包中看到的源码。
实际上,我们只需要了解:
1
System.arraycopy (elementData, index, elementData, index + 1, size - index);
copy
这个方法会移动index之后所有元素即可。这就意味着,ArrayList的add(int index, E element)函数,会引起index之后所有元素的改变。
通过上面的分析,我们就能理解为什么LinkedList中插入元素很快,而ArrayList中插入元素很慢。
接下来,我们看看 为什么LinkedList中随机访问很慢,而ArrayList中随机访问很快。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 返回LinkedList指定位置的元素
public E get(int index) {
return entry(index).element ;
}
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: " +index+
", Size: " +size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前先后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next ;
} else {
for (int i = size; i > index; i--)
e = e.previous ;
}
return e;
}
copy
从中,我们可以看出:通过get(int index)获取LinkedList第index个元素时。先是在双向链表中找到要index位置的元素;找到之后再返回。
下面在看看ArrayList随机访问的源码:
1
2
3
4
5
6
7
8
9
10
11
// 获取index位置的元素值
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: " +index+", Size: " +size);
}
copy
从中,我们可以看出:通过get(int index)获取ArrayList第index个元素时。直接返回数组中index位置的元素,而不需要像LinkedList一样进行查找。